Пайплайн обработки отказов и жалоб SES для чистых списков
Постройте пайплайн событий SES для bounce и complaint: сохраняйте события, автоматически подавляйте рискованные адреса и ведите аудиторский след, которому можно доверять.
Зачем нужен пайплайн отказов и жалоб
Bounce — это когда письмо не доставлено. Иногда это навсегда (адрес не существует). Иногда временно (почтовый ящик переполнен, сервер занят или поставщик ограничивает вас). Complaint — когда кто-то пометил письмо как спам или пожаловался, что оно нежелательно. Оба сигнала однозначно говорят: прекратите отправлять на этот адрес или, по крайней мере, приостановите и разберитесь.
Игнорирование таких сигналов быстро убивает доставляемость. Почтовые провайдеры учатся тому, что ваши письма создают проблемы, и всё больше будущих сообщений попадает в спам — даже хорошим лидам. Вы также тратите деньги на несуществующие адреса и время на людей, которые вовсе не видели ваше сообщение.
Пайплайн событий отказов и жалоб — это не про красивые аналитики. Это небольшая, надёжная система, которая:
- фиксирует каждое событие bounce и complaint
- быстро подавляет «плохие» адреса
- сохраняет поиск по аудиторскому следу
Последний пункт недооценивают чаще всего. Через неделю кто‑то спросит: «Мы вообще отправляли этому человеку?» или «Почему этот адрес был подавлен?» Если у вас только один флаг подавления и нет истории, уверенно ответить не получится.
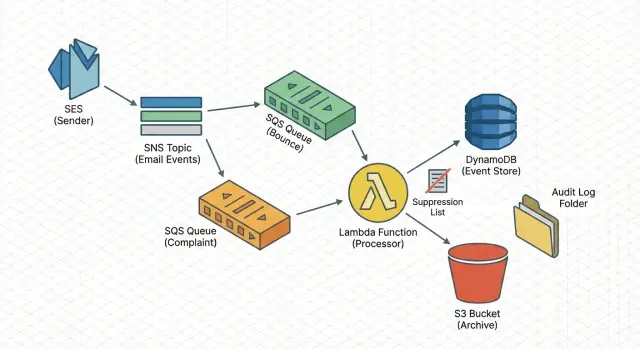
Ниже описанная схема использует стандартные блоки AWS (SNS, SQS, Lambda) для захвата событий, их безопасной обработки и сохранения. Это не про копирайтинг, источники списков, домены отправки или полную настройку SES.
Простая архитектура вкратце
Надёжный пайплайн должен быть скучным: каждое событие попадает в надёжное место, обрабатывается повторяемо и оставляет запись, к которой можно вернуться.
Поток (приём -> очередь -> обработка)
Проверенный путь такой:
SES публикует уведомления о bounce/complaint в SNS, SNS доставляет в SQS, а Lambda-воркер читает из SQS.
Такой подход сглаживает всплески, переживает краткие простои и позволяет повторять попытки, не блокируя отправку.
Что делает воркер
Держите Lambda узкой. Она должна валидировать, нормализовать, записать событие, а затем применять побочные эффекты (например, подавление). Типичные шаги:
- валидировать полезную нагрузку (сломанный JSON, отсутствует email, отсутствует тип)
- дедупать по ID события или по стабильному ключу, например
message_id + recipient_email + event_type - классифицировать событие (hard bounce, soft bounce, complaint)
- применить простое действие (suppress, warn-only, ignore)
- прикрепить контекст (sending domain, mailbox, campaign ID)
Хранение и действия (быстрый поиск и аудит)
Используйте два уровня хранения: один оптимизирован для быстрых запросов, другой — для долгосрочного подтверждения. Например:
- запись «последний статус по адресу» для быстрых запросов
- архив сырого payload для аудита и отладки
Из того же воркера вы можете триггерить действия: добавить адрес в список подавления, сигнализировать при всплеске жалоб и тегировать кампанию, чтобы отследить, какое сообщение вызвало проблему. Этот общий шаблон используют инструменты вроде LeadTrain, чтобы поддерживать чистую доставляемость при отправке через отдельные SES-настройки.
Настройте SES на публикацию событий отказов и жалоб
Во-первых, убедитесь, что SES посылает нужные сигналы при каждом отказе доставки или жалобе получателя.
В SES создайте configuration set (или используйте существующий, привязанный к исходящей почте) и включите публикацию событий для Bounce и Complaint. Оставляйте payload максимально близким к «сырым» данным. Вам понадобятся детали позже: timestamp, message ID, destination address, bounce type и complaint feedback.
Отделяйте среды. Используйте один SNS-топик для продакшена и другой для стейджинга, чтобы тестовая активность не портила реальные метрики.
Простая настройка:
- Создайте по одному SNS-топику на среду (например, ses-events-prod и ses-events-staging).
- В configuration set публикуйте события Bounce и Complaint в соответствующий SNS-топик.
- Подпишите SQS-очереди на SNS-топик. Многие команды используют одну операционную очередь для подавления/оповещений и отдельную для отчётности.
- Заблокируйте политику каждой SQS-очереди так, чтобы только ваш SNS-топик мог отправлять сообщения (ограничить по SourceArn и аккаунту).
- Отправьте небольшой тест и подтвердите, что получаете и bounce, и complaint сообщения с ожидаемыми полями.
Буферизация событий безопасно с помощью SQS
SQS — это буфер безопасности между событиями SES и вашим кодом. Он декуплирует систему, так что всплеск отказов или жалоб не перегрузит воркер. Если Lambda упадёт на несколько минут, события останутся в очереди вместо того, чтобы пропасть.
Для большинства пайплайнов Standard-очередь — самый простой выбор. Она может доставлять сообщения несколько раз, поэтому воркер должен быть идемпотентным (безопасным для повторного запуска). Выбирайте FIFO только если вам действительно нужна строгая упорядоченность или дедупликация на уровне очереди.
Standard vs FIFO простыми словами
FIFO имеет смысл, если вам нужна:
- строгая упорядоченность для одного и того же адреса
- дедупликация на уровне очереди
- предсказуемый, невысокий объём, который не упирается в ограничения FIFO
Dead-letter queue и лимиты повторных попыток
Используйте dead-letter queue (DLQ), чтобы "ядовитые" сообщения не блокировали нормальный трафик. Безопасная стартовая точка:
- max receives: 5–10
- retention сообщений: достаточно долго, чтобы расследовать (несколько дней обычно)
- тревоги, когда глубина DLQ больше 0
Держите сообщения компактными, но не выбрасывайте контекст. Храните полный SES event payload (или полный SNS message body), чтобы иметь возможность аудита в будущем. Если вы измените правила подавления, исходный payload позволит объяснить, почему адрес был подавлен.
Обработка событий небольшим Lambda-воркером
Lambda-воркер переводит события SES в решения, которые вам важны. Держите задачу узкой: распарсить одно сообщение, извлечь несколько полей, записать событие и обновить состояние подавления по необходимости.
Начните с нормализации payload SES в одну внутреннюю схему. Разные типы событий выглядят по-разному, поэтому выберите единый формат и маппируйте в него всё. Практический минимум:
- event_type (bounce, complaint, delivery)
- message_id (SES mail.messageId)
- recipient_email
- event_time (единый формат метки времени)
- source (configuration set, sending identity или имя системы)
Нормализуйте типы bounce на раннем этапе. Храните «bounce» как основной тип, а hard vs soft — отдельным полем. То же самое для complaints: сохраняйте детали подтипа, если они есть, но не позволяйте им фрагментировать основной поток.
Идемпотентность важна, потому что SQS может доставлять сообщения несколько раз. Используйте стабильный ключ, например message_id + recipient_email + event_type. Перед записью проверяйте, есть ли уже такой ключ. Если есть — подтверждайте сообщение и выходите. Это предотвращает двойное подавление и сохраняет корректность подсчётов.
Будьте строги с метками времени. Храните timestamp события в одном консистентном формате (например ISO), а также храните received_at отдельно, чтобы видеть задержки.
Хорошее практическое правило: сначала записывать событие, затем применять побочные эффекты. Если воркер упадёт после записи, но до подавления, вы можете позже безопасно повторить подавление, не потеряв аудита.
Храните события и для скорости, и для аудита
Вам нужно одновременно два свойства: быстрые ответы («можно ли отправлять на этот адрес?») и полный бумажный след, когда что-то пошло не так.
Храните небольшую сводку для быстрых запросов и держите сырой AWS payload отдельно. Сырой payload — ваш источник истины при расследовании всплесков жалоб или доказательств подавления адреса.
Сводная запись может быть небольшой:
- event_id (ваш уникальный ID)
- message_id (от SES)
- recipient (email)
- type и subtype (bounce, complaint; hard/soft)
- reason (короткий текст или код)
Распространённая пара — DynamoDB для быстрых запросов и S3 для архива. DynamoDB хорошо подходит, когда путь отправки должен быстро проверить «был ли этот получатель в bounce ранее?». S3 дешев для хранения сырых JSON в масштабе.
Один простой шаблон: записывать сводку в DynamoDB, сохранять сырой payload в S3 с ключом, включающим дату и message_id, и сохранять S3-ключ в записи DynamoDB.
Политика хранения — ваш выбор. Некоторые команды хранят сводки долго, а сырые данные удаляют раньше. Если вам нужен глубокий аудит — делайте наоборот.
Автоматически подавляйте плохие адреса (держите правила простыми)
Автоподавление — то место, где пайплайн окупается. Цель не в идеальной модели, а в том, чтобы быстро остановить известные плохие адреса и уметь объяснить решение позже.
Начните с правил, которые легко защитить:
- Hard bounce: подавлять немедленно.
- Complaint: подавлять немедленно.
- Soft bounce: подавлять только после N событий в скользящем окне (например, 3 soft bounce за 7 дней).
- Unsubscribe (если вы фиксируете отдельно): подавлять немедленно.
Soft bounces сложнее, потому что они могут быть временными. Правило порога не позволяет переусердствовать из-за одного плохого дня, но убирает адреса, которые стабильно не доходят.
Держите небольшой allowlist для внутренних доменов, тестовых почтовых ящиков и seed-адресов. Поддерживайте его компактным и периодически проверяйте, чтобы он не скрывал реальные проблемы.
Каждое подавление должно быть аудируемым. Храните:
- правило, которое вызвало подавление
- метаданные события, вызвавшего подавление (timestamp, message ID, тип bounce)
- контекст источника (campaign ID, sending domain, mailbox)
Такой бумажный след делает автоматизацию безопаснее и упрощает возврат в случае запроса: «Этот лид валиден, пожалуйста, уберите подавление».
Поддерживайте список подавления, которому можно доверять
Список подавления полезен только если все системы считают его источником правды. Это означает два требования: ясный статус для каждого получателя и одно место, которое проверяет статус перед каждой отправкой.
Многие команды обходятся тремя статусами:
- активный: можно отправлять
- подавлен: не отправлять
- на-проверке: пауза, пока человек не подтвердит
Путь отправки не должен догадываться. Перед отправкой делайте lookup и блокируйте отправку, если статус — подавлен или на-проверке. Делайте эту проверку в сервисе, который формирует список отправки, а не в панели, которую кто‑то может забыть использовать.
Восстановление (unsuppress) — место, где чаще всего делают ошибки. Делайте это доступным, но обдуманным: требуйте причину и фиксируйте, кто подтвердил. Если у вас несколько инструментов, упростите: только одна система может менять статус подавления, а все остальные должны обращаться к ней.
Также не перезаписывайте историю. Каждое изменение статуса должно создавать аудиторское событие: что поменялось, с чего на что, когда и что это вызвало.
Пример: адрес hard bounce в понедельник и автоматически подавлен. В четверг лид отвечает с корректным адресом. Сохраняйте старый адрес подавлённым, пометьте новый как активный и зафиксируйте оба изменения с заметками. В платформах вроде LeadTrain такая история помогает логике обработки ответов и отправки полагаться на единое решение по подавлению.
Распространённые ошибки и как их избегать
Пайплайн может выглядеть завершённым в первый день и при этом принимать плохие решения позже. Большинство проблем происходят из мелких предположений, которые искажают метрики или вызывают неверное подавление.
Одна ловушка — считать «delivered» равным «вошло в inbox». SES сообщает лишь о том, что принимающий сервер принял сообщение, а не о том, где оно оказалось. Используйте delivery как сигнал здоровья отправки, а не как доказательство попадания в inbox.
Ещё одна ошибка — обращаться со всеми bounce одинаково. Временный bounce не равен постоянному. Слишком агрессивное подавление уменьшает список и может скрыть реальные проблемы, такие как скорость отправки, содержание или репутация нового домена.
Типичные ошибки и исправления:
- Нет повторных попыток: если воркер упал, событие исчезает. Исправление: SQS + retries + DLQ + идемпотентная обработка.
- Нет ключа дедупа: одно и то же событие обработано дважды. Исправление: храните уникальный event ID и игнорируйте повторы.
- Подавление по каждому bounce: временные проблемы становятся постоянными штрафами. Исправление: подавляйте сразу hard bounce и жалобы; для soft bounce используйте пороги.
- Хранение только агрегатов: вы не можете ответить «почему это подавлено?». Исправление: храните сырые события с message ID, timestamp и правилом, которое сработало.
- Считать доставку равной попаданию в ящик: метрики выглядят хорошо, а ответы падают. Исправление: разделяйте delivered и engaged и отслеживайте отклики по mailbox и domain.
Пример: вы отправили 2000 писем и видите 1980 delivered. Если 30 soft bounce с одного домена подавляются сразу, вы можете убрать валидные лиды. Лучшее правило: «подавлять только hard bounce и complaints; soft bounce подавлять только после 3 событий за 7 дней», с записью аудита для каждого решения.
Быстрый чеклист для поддержания пайплайна
Пайплайн полезен только если ему доверяют неделями.
Простая рутина (ежедневно или несколько раз в неделю):
- Подтвердите поток событий: глубина очереди должна меняться при отказах/жалобах.
- Проверьте DLQ: обычно он должен быть пуст. Если нет — изучите несколько сообщений, исправьте причину и проиграйте безопасно.
- Сверьте пару получателей: выберите несколько недавно отправленных адресов и убедитесь, что видите их историю событий и метки времени.
- Убедитесь, что подавление применяется перед отправкой: проверка подавления должна происходить до постановки письма в очередь отправки.
- Раз в неделю экспортируйте выборку аудита: проверьте ключевые поля (recipient, event type, reason codes, message ID, campaign ID, timestamp).
Хорошая проверка: выберите 3 адреса, которые bounced, и 2, которые ответили. Вы должны проследить каждый кейс от попытки отправки до финального результата без догадок, какая система содержит правду.
Если вы отправляете из платформы вроде LeadTrain, цель та же: полный трек событий и автоматическое подавление, чтобы команда тратила время на качественные лиды, а не на подплатку данных.
Пример: реальная неделя исходящих событий
Небольшая SDR‑команда запускает sequence из 600 писем на целевой список. Их пайплайн уже настроен, поэтому каждый bounce и complaint фиксируется, сохраняется и обрабатывается без постоянного контроля.
В понедельник один адрес hard bounces (пользователь не существует). В течение секунд событие хранится и адрес подавляется. Следующая попытка отправки в последовательности в среду блокируется ещё до выхода. Никаких повторных bounce и дополнительного вреда.
К четвергу другой получатель нажимает «Report spam» после первого письма. Жалобы — срочные, поэтому адрес подавляется немедленно, даже если follow-up был бы позже в тот же день.
Лог событий команды может выглядеть так:
- Mon 10:14:12 - Hard bounce - [email protected] - suppressed (reason: bounce)
- Wed 09:00:03 - Send blocked - [email protected] - already suppressed
- Thu 15:27:40 - Complaint - [email protected] - suppressed (reason: complaint)
- Fri 11:05:18 - Manager review - why did alex stop? - full trail shown
В пятницу менеджер спрашивает, почему [email protected] перестал получать письма. Вместо догадок вы показываете payload bounce, действие подавления и заблокированную попытку отправки. Это и есть разница между «оно пропало» и «вот цепочка событий».
Ошибки тоже случаются. Если bounce был из‑за опечатки в загруженном списке, и правильный адрес — [email protected], не удаляйте записи без следа. Храните одобренный unsuppress (кто запросил, когда и почему) и добавьте исправленный адрес как нового получателя.
Следующие шаги: выпустите минимальную версию и итерационно улучшайте
Выберите одно достижимое первое действие: надёжный приём, долговременное хранение или автоматическое подавление. Попытка довести все три до совершенства в первый день — частая причина, почему проекты застывают.
Практический порядок: сначала приём (чтобы не терять данные), затем хранение (чтобы отвечать на вопросы), затем подавление (чтобы действовать).
Маленький первый релиз, который уже даёт эффект:
- Захватывать события Bounce и Complaint в одну очередь и логировать каждое сообщение.
- Хранить сырой payload плюс несколько нормализованных полей (timestamp, type, mailbox, message_id).
- Сначала применять только два действия подавления: hard bounces и complaints.
- Добавить простой lookup: «Почему этот адрес подавлен?».
Держите правила простыми на первую неделю, затем расширяйте по наблюдаемым данным. Если для одного домена резко выросло количество transient bounces, можно добавить временное правило паузы для этого домена, вместо подавления всех адресов.
Опишите схему событий и правила подавления простым языком и держите это в одном месте, которое команда действительно прочитает.
Если хотите меньше движущихся частей, LeadTrain — пример платформы для cold email, которая объединяет домены, почтовые ящики, разогрев, sequences и классификацию ответов в одном рабочем процессе, при этом опираясь на те же принципы: точные события, быстрое подавление и прозрачный аудит.
Часто задаваемые вопросы
What’s the difference between a bounce and a complaint, and why should I care?
Отказ (bounce) означает, что сообщение не удалось доставить; жалоба (complaint) — когда получатель пометил письмо как спам или сообщил, что оно нежелательно. Практическое правило — рассматривать оба сигнала как «прекратить отправку», потому что игнорирование быстро ухудшает доставляемость и тратит отправки попусту.
What’s the simplest AWS setup for capturing SES bounces and complaints?
Начните с проверенного пути: SES публикует события Bounce и Complaint в SNS, SNS передаёт их в SQS, а Lambda читает из SQS. Это помогает не терять события при всплесках или кратких сбоях и делает повторные попытки безопасными.
Should I separate production and staging for SES event pipelines?
Да. Используйте отдельные SNS-топики и очереди для продакшена и для стейджинга, чтобы тестовые отказы и жалобы не смешивались с реальными данными. Это также безопаснее для отладки: вы можете менять правила в стейджинге, не рискуя списком подавления в продакшене.
Should I use an SQS Standard queue or FIFO for SES events?
Обычно Standard-очередь — лучший выбор: она масштабируется и проста, но может доставлять сообщения более одного раза. Это нормально, если ваша Lambda идемпотентна (то есть повторная обработка того же события не ведёт к двойным действиям).
How do I handle bad or malformed SES events without breaking the pipeline?
Используйте dead-letter queue, чтобы «плохие» сообщения не блокировали нормальный поток, и ставьте max receive count в районе 5–10. Если в DLQ попадает сообщение, разберите причину, исправьте парсинг или валидацию и повторно проиграйте только после фикса, иначе ошибки повторятся.
What should my Lambda worker do (and not do)?
Держите Lambda узкой: валидируйте полезную нагрузку, нормализуйте поля в одну внутреннюю схему, дедупайте по стабильному ключу, сохраняйте событие, а затем выполняйте побочные эффекты вроде подавления. Сначала записать событие, потом подавление — безопаснее, потому что при падении функции у вас останется аудиторская запись.
How do I prevent double-processing when SQS delivers the same message twice?
Предполагайте, что дубликаты будут и дедупайте по стабильному ключу, например message_id + recipient_email + event_type. Сохраняйте этот ключ и обрабатывайте повторы как no-op, чтобы не подавлять дважды и не завышать счётчики отказов и жалоб.
How should I store events so I can both query fast and audit later?
Храните два уровня: быстрый «последний статус для адреса» для проверок перед отправкой и архив «сырой» полезной нагрузки для аудита и отладки. Распространённая схема — сводка в DynamoDB и исходные JSON в S3, с сохранённым S3-ключом в записи DynamoDB.
What are good default auto-suppression rules for bounces and complaints?
Начните с простых защищаемых правил: подавлять сразу по hard bounce и по жалобе; soft bounce подавлять только после порога, например 3 события в течение 7 дней. Сохраняйте правило, которое вызвало подавление, вместе с message ID и меткой времени — это объясняет решения позже.
How do I make sure suppression is actually enforced and reversible safely?
Считайте список подавления источником правды и проверяйте его перед каждой отправкой, а не в панели, которую могут забыть использовать. Сделайте возможность восстановить адрес, но требуйте причину и фиксируйте, кто одобрил восстановление; при этом храните всю историю событий.