Pipeline de eventos de falhas e reclamações do SES para manter listas limpas
Construa um pipeline de eventos de falhas e reclamações do SES para armazenar eventos, suprimir endereços arriscados automaticamente e manter uma trilha de auditoria confiável para a equipe.
Por que você precisa de um pipeline de bounces e reclamações
Um bounce ocorre quando um e‑mail não pode ser entregue. Às vezes é permanente (o endereço não existe). Às vezes é temporário (caixa cheia, servidor ocupado ou o provedor está limitando). Uma complaint acontece quando alguém marca seu e‑mail como spam ou o reporta como indesejado. Ambos são sinais claros para parar de enviar para aquele endereço, ou ao menos pausar e investigar.
Ignorar esses sinais faz a entregabilidade cair rápido. Os provedores de e‑mail percebem que suas mensagens causam problemas, então e‑mails futuros vão para spam — mesmo para leads bons. Você também perde dinheiro enviando para endereços mortos e perde tempo atrás de pessoas que nunca viram sua mensagem.
Um pipeline de eventos de bounce e complaint não é sobre análises sofisticadas. É um sistema pequeno e confiável que:
- captura todo evento de bounce e complaint
- suprime endereços ruins rapidamente
- mantém uma trilha de auditoria pesquisável
Essa última parte é fácil de subestimar. Uma semana depois alguém vai perguntar “Realmente enviamos para essa pessoa?” ou “Por que esse endereço foi suprimido?” Se você só guardar uma flag de supressão sem histórico, não conseguirá responder com confiança.
A configuração abaixo usa blocos comuns da AWS (SNS, SQS, Lambda) para capturar eventos, processá‑los com segurança e armazená‑los. Não cobre copywriting, origem de listas, domínios de envio ou configuração completa do SES.
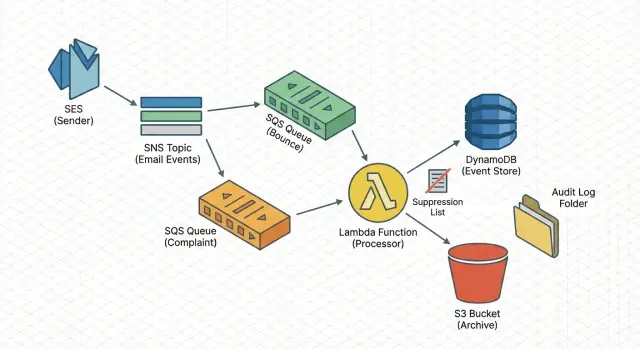
A arquitetura simples em resumo
Um pipeline confiável deve ser entediante: todo evento aterra em um lugar seguro, é processado de forma repetível e deixa um registro que você pode consultar depois.
O fluxo (ingest → fila → trabalho)
Um caminho comprovado é:
SES envia notificações de bounce/complaint para o SNS, o SNS entrega para a SQS, e um worker Lambda lê da SQS.
Essa abordagem absorve picos, sobrevive a curtas indisponibilidades e permite retries sem bloquear seus envios.
O que o worker faz
Mantenha a Lambda focada. Ela deve validar, normalizar, gravar o evento e então aplicar efeitos colaterais (como supressão). Passos típicos:
- validar o payload (JSON malformado, e‑mail ausente, tipo ausente)
- dedup: usar um ID de evento ou uma chave estável como
message_id + recipient_email + event_type - classificar o evento (hard bounce, soft bounce, complaint)
- aplicar uma ação simples (suprimir, apenas avisar, ignorar)
- anexar contexto (domínio de envio, caixa, ID da campanha)
Armazenamento + ações (busca rápida e auditoria)
Use duas camadas de armazenamento: uma otimizada para consultas rápidas e outra para prova de longo prazo. Por exemplo:
- um registro de “último status por endereço” para pesquisas rápidas
- um arquivo do payload bruto do evento para auditoria e debugging
Do mesmo worker você pode disparar ações: adicionar o endereço à lista de supressão, alertar quando a taxa de reclamações subir, e marcar a campanha para rastrear qual mensagem causou o problema. Esse é o mesmo padrão geral que ferramentas como LeadTrain usam para manter a entregabilidade limpa quando enviam por setups separados do SES.
Configure o SES para publicar eventos de bounce e complaint
Primeiro, garanta que o SES emita os sinais corretos sempre que um e‑mail falhar ou um destinatário reclamar.
No SES, crie um configuration set (ou reutilize um já anexado aos e‑mails de saída) e ative a publicação de eventos para Bounce e Complaint. Mantenha o payload o mais próximo do bruto possível. Você vai querer detalhes depois: timestamp, message ID, endereço de destino, tipo de bounce e feedback da complaint.
Trate ambientes separadamente. Use um tópico SNS para produção e outro para staging para que atividade de teste não polua métricas reais.
Uma configuração direta:
- Crie um tópico SNS por ambiente (por exemplo, ses‑events‑prod e ses‑events‑staging).
- No configuration set, publique eventos de Bounce e Complaint no tópico SNS correspondente.
- Assine filas SQS ao tópico SNS. Muitas equipes usam uma fila operacional para supressão/alertas e outra separada para relatórios.
- Restrinja a política de cada fila SQS para que apenas seu tópico SNS possa enviar mensagens (restrinja pelo SourceArn e conta).
- Envie um pequeno lote de teste e confirme que você recebe mensagens de bounce e complaint com os campos esperados.
Bufferize eventos com segurança usando SQS
A SQS é o buffer de segurança entre os eventos do SES e seu código. Ela desacopla o sistema para que um pico de bounces ou reclamações não sobrecarregue seu worker. Se a Lambda ficar fora do ar por alguns minutos, os eventos aguardam na fila em vez de desaparecer.
Para a maioria dos pipelines, uma fila Standard é a escolha mais simples. Ela pode entregar mensagens mais de uma vez, então o worker precisa ser idempotente (seguro para executar duas vezes). Escolha FIFO apenas se realmente precisar de ordenação estrita ou deduplicação no nível da fila.
Standard vs FIFO em palavras simples
FIFO pode fazer sentido se você precisar de:
- ordenação estrita para o mesmo endereço de e‑mail
- deduplicação no nível da fila
- volume previsível e menor que não vai atingir limites do FIFO
Dead‑letter queue e limites de retry
Use uma dead‑letter queue (DLQ) para que mensagens venenosas não bloqueiem o tráfego saudável. Um ponto de partida seguro:
- max receives: 5 a 10
- retenção de mensagem: tempo suficiente para investigar (alguns dias é comum)
- alarmes quando a profundidade da DLQ for maior que 0
Mantenha as mensagens pequenas, mas não descarte contexto. Armazene o payload AWS completo (ou o corpo completo da mensagem do SNS) para auditoria futura. Se você mudar regras de supressão no futuro, o payload original é o que permite explicar por que um endereço foi suprimido.
Processe eventos com um worker Lambda pequeno
O worker Lambda traduz eventos SES nas decisões que importam. Mantenha a tarefa estreita: parse uma mensagem, extraia alguns campos, grave um registro de evento e atualize o estado de supressão quando necessário.
Comece normalizando os payloads do SES em um esquema interno. Tipos de eventos diferentes nem sempre têm o mesmo formato, então escolha uma forma consistente e mapeie tudo para ela. Um mínimo prático:
- event_type (bounce, complaint, delivery)
- message_id (SES mail.messageId)
- recipient_email
- event_time (um timestamp consistente)
- source (configuration set, identidade de envio ou nome do sistema)
Normalize tipos de bounce cedo. Mantenha “bounce” como o tipo principal e guarde hard vs soft como um campo separado. Faça o mesmo para complaints: armazene subtipos se existirem, mas não deixe que fragmentem seu fluxo central.
Idempotência importa porque a SQS pode entregar mensagens mais de uma vez. Use uma chave estável como message_id + recipient_email + event_type. Antes de gravar, verifique se você já armazenou essa chave. Se sim, reconheça e saia. Isso evita dupla supressão e mantém as contagens honestas.
Seja rígido com timestamps. Armazene o timestamp do evento em um formato consistente (por exemplo, strings ISO). Também salve received_at separadamente para que você possa detectar atrasos.
Uma boa regra prática: grave o registro de evento primeiro e então aplique efeitos colaterais. Se o worker falhar depois de gravar mas antes de suprimir, você pode executar a supressão com segurança depois sem perder a trilha de auditoria.
Armazene eventos para velocidade e trilha de auditoria
Você quer duas coisas ao mesmo tempo: respostas rápidas (“este endereço é seguro para enviar?”) e um histórico completo quando algo parece errado.
Armazene um resumo pequeno que você possa consultar rápido e mantenha o JSON bruto separado. O payload bruto é sua fonte da verdade quando precisar explicar um pico de reclamações ou provar por que um endereço foi suprimido.
Um registro de resumo pode ser pequeno:
- event_id (seu ID único)
- message_id (do SES)
- recipient (endereço de e‑mail)
- type e subtype (bounce, complaint; hard/soft)
- reason (texto curto ou código)
Uma combinação comum é DynamoDB para buscas rápidas e S3 para arquivo. O DynamoDB funciona bem quando seu caminho de envio precisa de um check rápido “esse destinatário já bouncou antes?”. O S3 é barato para armazenar JSON bruto em escala.
Um padrão simples: grave o resumo no DynamoDB, armazene o payload bruto no S3 usando uma chave que inclua data e message_id, e salve essa chave do S3 no registro do DynamoDB.
Retenção é uma escolha de política. Algumas equipes mantêm resumos a longo prazo e expiram payloads brutos mais cedo. Se você precisa de auditorias profundas, faça o oposto.
Supressão automática de endereços ruins (mantenha regras simples)
A auto‑supressão é onde o pipeline compensa. O objetivo não é um modelo perfeito. É parar endereços comprovadamente ruins rapidamente e poder explicar a decisão depois.
Comece com regras fáceis de defender:
- Hard bounce: suprimir imediatamente.
- Complaint: suprimir imediatamente.
- Soft bounce: suprimir apenas após N eventos em uma janela móvel (por exemplo, 3 soft bounces em 7 dias).
- Cancelamento de inscrição (se capturado separadamente): suprimir imediatamente.
Soft bounces são complicados porque podem ser temporários. A regra de limite evita reação exagerada a um dia ruim, enquanto ainda remove endereços que falham repetidamente.
Mantenha uma pequena allowlist para domínios internos, caixas de teste e endereços seed. Mantenha‑a restrita e revisada para que não esconda problemas reais.
Cada supressão deve ser auditável. Armazene:
- a regra que disparou a supressão
- os metadados do evento que a acionou (timestamp, message ID, tipo de bounce)
- o contexto de origem (ID da campanha, domínio de envio, caixa)
Esse histórico torna a automação mais segura e facilita reversões quando alguém diz “Esse lead é válido, por favor reative.”
Mantenha uma lista de supressão confiável
Uma lista de supressão só ajuda se todo mundo a tratar como fonte da verdade. Isso significa duas coisas: um status claro por destinatário e um único ponto que o sistema de envio verifica antes de cada envio.
Muitas equipes se dão bem com três status:
- ativo: ok para enviar
- suprimido: não enviar
- pendente‑revisão: pausado até um humano confirmar
O caminho de envio não deve adivinhar. Antes de um e‑mail ser enviado, faça uma consulta e bloqueie o envio se o status for suprimido ou pendente‑revisão. Coloque essa verificação no serviço que constrói a lista de envio, não num painel que alguém pode esquecer.
Reativar é onde erros acontecem. Permita, mas de forma deliberada. Exija um motivo e registre quem aprovou. Se você tem múltiplas ferramentas, mantenha simples: só um sistema pode alterar o status de supressão e todo o resto deve chamá‑lo.
Também, não sobrescreva histórico. Toda mudança de status deve criar um evento de auditoria: o que mudou, de qual para qual estado, quando e o que o disparou.
Exemplo: um endereço hard bounces na segunda e é suprimido automaticamente. Na quinta, o lead responde a partir de um e‑mail corrigido. Você mantém o endereço antigo suprimido, marca o novo como ativo e registra ambas as alterações com notas. Em plataformas como LeadTrain, esse tipo de histórico ajuda classificação de respostas e lógica de envio a depender de uma decisão de supressão consistente.
Erros comuns e como evitá‑los
Um pipeline pode parecer pronto no dia um e ainda tomar decisões ruins depois. A maioria dos problemas vem de pequenas suposições que distorcem métricas ou disparam supressões erradas.
Uma armadilha é tratar “delivered” como “chegou na caixa de entrada”. O SES pode dizer que o servidor receptor aceitou a mensagem, não onde ela aterrissou. Use delivery como um sinal de saúde de envio, não como prova de colocação na caixa de entrada.
Outro problema é tratar todos os bounces igual. Um bounce transitório não deve receber a mesma reação que um bounce permanente. Supressão excessiva encolhe sua lista e pode esconder problemas reais como pacing, conteúdo ou reputação de novo domínio.
Erros comuns e correções:
- Sem retries: se seu worker falha, o evento desaparece. Correção: SQS + retries + DLQ + processamento idempotente.
- Sem chave de dedupe: o mesmo evento é processado duas vezes. Correção: armazene um ID único e ignore repetições.
- Suprimir em todo bounce: problemas temporários viram penalidades permanentes. Correção: suprimir hard bounces e complaints imediatamente; usar thresholds para soft bounces.
- Armazenar só agregados: você não consegue responder “por que isso foi suprimido?”. Correção: armazene eventos brutos com message IDs, timestamps e a regra que disparou.
- Assumir que entrega = inbox: métricas parecem boas enquanto respostas caem. Correção: separe delivered de engaged e monitore taxas de resposta por mailbox e domínio.
Exemplo: você envia 2.000 e‑mails e vê 1.980 entregues. Se 30 forem soft bounces de um único domínio e você os suprimir imediatamente, pode remover leads válidos. Uma regra melhor é “suprimir apenas hard bounces e complaints, e suprimir soft bounces apenas após 3 eventos em 7 dias”, com um registro de auditoria para cada decisão.
Checklist rápido para manter o pipeline saudável
Um pipeline só ajuda se você puder confiar nele semana após semana.
Uma rotina simples (diária ou algumas vezes por semana):
- Confirme que os eventos fluem: a profundidade da fila deve variar quando bounces/reclamações ocorrem.
- Verifique a DLQ: normalmente deve estar vazia. Se não estiver, inspecione algumas mensagens, corrija a causa e reprocesse com segurança.
- Verifique destinatários aleatoriamente: escolha alguns endereços recentemente enviados e confirme que você vê o histórico de eventos e timestamps.
- Verifique se a supressão é aplicada antes do envio: checagens de supressão devem ocorrer antes que um e‑mail seja enfileirado para envio.
- Exporte uma amostra de auditoria semanalmente: confirme campos-chave (recipient, event type, reason codes, message ID, campaign ID, timestamp).
Um teste rápido que funciona bem: escolha 3 endereços que bouncem e 2 que responderam. Você deve conseguir traçar cada um desde o envio tentado até o resultado final sem adivinhar qual sistema é a fonte da verdade.
Se você envia por uma plataforma como LeadTrain, o objetivo é o mesmo: manter a trilha de eventos completa e a supressão automática, para que sua equipe gaste tempo com bons leads em vez de consertar falhas de dados.
Exemplo: uma semana real de outreach
Uma pequena equipe de SDR envia uma sequência de 600 e‑mails a uma lista segmentada. O pipeline já está montado, então todo bounce e complaint é capturado, armazenado e tratado sem supervisão manual.
Na segunda, um endereço hard bounces (usuário não existe). Em segundos, o evento é armazenado e o endereço é suprimido. O próximo passo da sequência tenta enviar na quarta, mas o envio é bloqueado antes de sair do sistema. Sem bounces repetidos, sem dano extra.
Na quinta, um prospect clica em “Report spam” após o primeiro e‑mail. Reclamações são urgentes, então o endereço é suprimido imediatamente, mesmo que um follow‑up fosse enviado mais tarde naquele dia.
O log de eventos da equipe pode ficar assim:
- Seg 10:14:12 - Hard bounce - [email protected] - suprimido (motivo: bounce)
- Qua 09:00:03 - Envio bloqueado - [email protected] - já suprimido
- Qui 15:27:40 - Complaint - [email protected] - suprimido (motivo: complaint)
- Sex 11:05:18 - Revisão do gerente - por que alex parou? - trilha completa exibida
Na sexta, um gerente pergunta por que [email protected] parou de receber e‑mails. Em vez de adivinhar, você mostra o payload do bounce, a ação de supressão e a tentativa de envio bloqueada depois. Essa é a diferença entre “desapareceu” e “aqui está a cadeia de eventos”.
Erros acontecem também. Se o bounce foi causado por um erro de digitação na lista e o endereço correto é [email protected], não apague entradas silenciosamente. Mantenha um registro de reativação aprovado (quem solicitou, quando e por quê) e adicione o endereço corrigido como novo destinatário.
Próximos passos: entregue uma versão pequena e itere
Escolha um resultado para entregar primeiro: ingestão confiável, armazenamento durável ou supressão automática. Tentar aperfeiçoar os três no dia um é como fazer o pipeline travar.
Uma ordem prática é ingestão primeiro (pare de perder dados), depois armazenamento (responda perguntas depois) e então supressão (trate os casos automaticamente).
Um primeiro release pequeno que já compensa:
- Capture eventos de bounce e complaint do SES em uma fila e registre cada mensagem.
- Armazene o payload bruto mais alguns campos normalizados (timestamp, tipo, mailbox, message_id).
- Aplique apenas duas ações de supressão inicialmente: hard bounces e complaints.
- Adicione uma consulta simples: “Por que esse endereço foi suprimido?”
Mantenha as regras pequenas por uma semana e depois expanda com base no que você realmente vê. Se soft bounces transitórios aumentarem para um domínio, talvez adicione uma regra de pausa temporária para aquele domínio em vez de suprimir todos os endereços.
Anote seu esquema de evento e regras de supressão em linguagem simples e mantenha‑os em um lugar que a equipe realmente leia.
Se você quer menos peças móveis, LeadTrain é um exemplo de plataforma all‑in‑one de cold email que reúne domínios, caixas, aquecimento, sequências e classificação de respostas num fluxo só, mantendo os mesmos fundamentos: eventos precisos, supressão rápida e trilha de auditoria clara.
Perguntas Frequentes
Qual a diferença entre bounce e complaint, e por que devo me importar?
Uma bounce (falha) significa que o e-mail não pôde ser entregue; uma complaint (reclamação) significa que o destinatário marcou sua mensagem como spam ou indesejada. O padrão prático é tratar ambos como sinais de “parar de enviar”, porque ignorá‑los prejudica rapidamente a entregabilidade e faz você desperdiçar envios.
Qual a configuração AWS mais simples para capturar bounces e complaints do SES?
Comece com o caminho simples e confiável: o SES publica eventos de Bounce e Complaint no SNS, o SNS faz fan‑out para SQS, e uma Lambda lê da SQS. Isso evita perder eventos durante picos ou breves falhas e torna as tentativas de reprocessamento seguras.
Devo separar produção e staging para pipelines de evento do SES?
Use tópicos SNS e filas separados por ambiente para que bounces e reclamações de teste não poluam os dados de produção. Também facilita depuração porque você pode alterar regras em staging sem arriscar a lista de supressão real.
Devo usar uma fila SQS Standard ou FIFO para eventos do SES?
Uma fila Standard é a escolha padrão porque escala e é simples, mas pode entregar mensagens mais de uma vez. Isso é aceitável se sua Lambda for idempotente — ou seja, reprocessar o mesmo evento não cria contagens duplicadas nem supressões duplas.
Como devo lidar com eventos SES ruins ou malformados sem quebrar o pipeline?
Use uma dead‑letter queue para que mensagens inválidas não bloqueiem o tráfego bom, e configure um max receive como 5–10. Se a DLQ receber mensagens, investigue a causa e só reprocesse depois de corrigir a validação ou parsing, caso contrário vai falhar de novo.
O que a minha função Lambda deve fazer (e o que não deve)?
Mantenha o trabalho da Lambda estreito: valide o payload, normalize campos em um esquema interno, dedupe usando uma chave estável, armazene o evento e então aplique efeitos colaterais como supressão. Escrever o evento antes de suprimir é mais seguro porque mantém a trilha de auditoria se a função falhar no meio do processo.
Como evito o reprocessamento duplo quando a SQS entrega a mesma mensagem duas vezes?
Pressuponha que duplicatas ocorrerão e dedupe com uma chave estável como message_id + recipient_email + event_type. Armazene essa chave e trate repetições como no‑ops para não suprimir duas vezes nem inflar contagens.
Como devo armazenar eventos para poder consultar rápido e auditar depois?
Mantenha duas camadas: um registro rápido de “último status por endereço” para verificações no momento do envio, e um arquivo de eventos brutos para auditoria e debugging. Um padrão comum é resumo no DynamoDB e JSON bruto no S3, salvando a chave do S3 no registro do DynamoDB.
Quais são boas regras padrão de auto‑supressão para bounces e complaints?
Comece com regras fáceis de defender: suprimir hard bounces e reclamações imediatamente; suprimir soft bounces apenas após um limite (por exemplo, 3 em 7 dias). Registre a regra que disparou a supressão junto com message ID e timestamp para poder explicar decisões.
Como garanto que a supressão é realmente aplicada e reversível com segurança?
Trate a lista de supressão como a fonte da verdade e faça a verificação antes de cada envio — não confie num dashboard que alguém pode esquecer de usar. Permita reativar, mas de forma deliberada: exija um motivo e registre quem aprovou, mantendo todos os eventos históricos intactos.