Do sandbox ao produção no AWS SES para envio outbound: um plano
Etapas para sair do sandbox do AWS SES e ir para produção em envios outbound, com um plano prático de limites, ramp e monitoramento para não ficar bloqueado ao escalar.
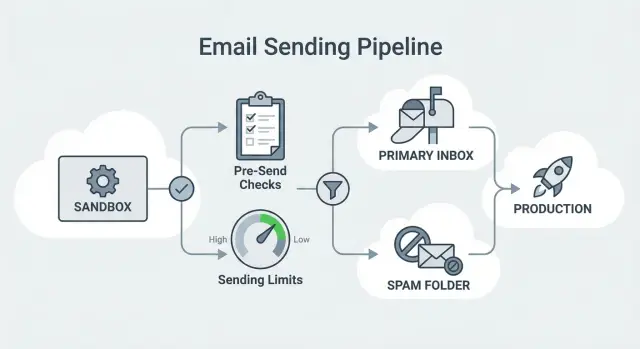
Por que o sandbox do SES bloqueia aumentos de envio\n\nQuando você cria (ou ativa) o Amazon Simple Email Service (SES), sua conta normalmente começa no sandbox do SES. É um modo de segurança: a AWS permite testes de envio, mas coloca limites rígidos até você provar que envia com responsabilidade.\n\nEsses limites são um problema real para outreach frio. No sandbox você fica restrito a baixo volume diário, baixa velocidade por segundo e (o mais importante) apenas destinatários verificados. Essa última regra bloqueia o outbound por completo: você não pode enviar para prospects reais a menos que verifique cada endereço ou domínio primeiro.\n\nPor isso equipes frequentemente encontram atrito ao passar do “AWS SES sandbox para produção”. Você pode ter sua sequência pronta, sua lista importada e um plano de ramp, e ainda descobrir que o primeiro lote não envia — ou envia tão devagar que os follow-ups se perdem e a campanha perde ritmo.\n\nUm padrão comum de falha parece com isto:\n\n- Testes para alguns endereços internos funcionam, então tudo parece pronto.\n- Você lança para prospects e os envios falham porque os destinatários não são verificados.\n- Após a aprovação, sua taxa de envio ainda é baixa o suficiente para que os passos se espalhem e os resultados caiam.\n- Ao aumentar o volume, erros de throttle forçam pausas enquanto você solicita limites maiores.\n\nIsso atinge times de SDR e fundadores especialmente forte porque eles precisam de um fluxo diário constante. Se seu plano depende de envio consistente (por exemplo, 200 prospects novos por dia em sequências multi-step), o sandbox transforma outreach em trabalho de para-e-vai.\n\nMais um detalhe: o sandbox não é um teste realista de entregabilidade. A entregabilidade real depende de autenticação, warm-up, qualidade da lista, controle de bounces/reclamações e um ramp gradual. O sandbox existe principalmente para desacelerar até a AWS ter confiança de que você não vai causar abuso ou má experiência aos destinatários.\n\n## Sandbox vs produção: o que realmente muda\n\nSandbox e produção diferem nas coisas que importam para outbound.\n\nNo sandbox, você só pode enviar para identidades verificadas (endereços de e-mail específicos ou domínios inteiros que você verificou). Na produção, você pode enviar para destinatários reais sem verificar cada um.\n\nSeus limites também mudam. As cotas do sandbox são pequenas. As cotas da produção são maiores, mas ainda aplicadas. Você ainda pode atingir limites diários e throttles por segundo, e a AWS pode ajustar cotas com base no seu histórico de envio.\n\nA outra grande mudança é a reputação. No sandbox você não constrói histórico significativo. Na produção, taxas de bounce e reclamação começam a moldar sua capacidade de escalar a longo prazo.\n\nNa prática, equipes de outbound sentem três diferenças imediatas:\n\n- Quem você pode e-mailar: apenas verificados vs envio aberto\n- Quão rápido pode enviar: limites baixos vs cotas maiores (ainda limitadas)\n- Quanto os erros importam: métricas de produção afetam rapidamente reputação e throughput\n\n### O que a AWS realmente avalia\n\nQuando você solicita acesso à produção (e depois de ser aprovado), a AWS busca sinais de que você não vai prejudicar destinatários ou redes. Dois métricas importam mais:\n\n- Taxa de bounce: bounces altos geralmente significam higiene ruim da lista.\n- Taxa de reclamação: reclamações indicam e-mails indesejados, segmentação ruim ou conteúdo enganoso.\n\nA AWS também se importa com seu caso de uso e como você trata opt-outs. Para outbound, isso geralmente significa: você está enviando para pessoas que razoavelmente podem esperar sua mensagem, e elas conseguem parar de receber facilmente?\n\nO acesso à produção não é a linha de chegada. É permissão para operar em escala real. Se você subir rápido demais, ignorar unsubscribes ou enviar para listas fracas, ainda pode ser throttled ou forçado a desacelerar.\n\n## Preparação antes de aplicar\n\nAntes de pedir à AWS para mover você do sandbox para produção, prepare sua base de envio. Aprovações do SES (e estabilidade a longo prazo) ficam muito mais fáceis quando sua identidade e processos parecem intencionais.\n\nComece com um domínio de envio dedicado, separado do seu domínio corporativo principal. Muitas equipes usam um domínio relacionado para que experiências de outbound não coloquem em risco a reputação da caixa principal.\n\nEm seguida, configure autenticação: SPF, DKIM e DMARC. Você não precisa de uma política DMARC agressiva no primeiro dia, mas precisa de alinhamento. Uma meta simples é:\n\n- Assinatura DKIM do SES corresponde ao domínio no seu From\n- SPF está publicado\n- DMARC está publicado para que provedores verifiquem legitimidade\n\nTambém decida identidade e tratamento de respostas antecipadamente:\n\n- Use um From que pareça uma pessoa real ou time.\n- Use um endereço que consiga receber respostas.\n- Mantenha os detalhes do From estáveis (não rotacione nomes e endereços toda semana).\n\nPor fim, comprometa-se com uma regra clara de unsubscribe. Mesmo em outbound frio, “pare” deve significar pare — imediatamente e consistentemente em todas as listas e sequências.\n\nSe quiser uma configuração operacional mais simples, o LeadTrain (leadtrain.app) foi construído para manter domínios, caixas, warm-up, sequências e classificação de respostas em um só lugar, para que menos detalhes escapem durante a configuração.\n\n## Passo a passo: solicitar acesso à produção no SES\n\nIr para produção é um pedido de suporte. Suas respostas importam tanto quanto a configuração técnica.\n\n### 1) Encontre o pedido no console da AWS\n\nAbra o Amazon SES na região AWS de onde você vai enviar. Na área de status da conta (onde mostra que você está no sandbox), escolha a opção para solicitar acesso à produção ou aumento de limite de envio. Isso abre um formulário de support case.\n\n### 2) Descreva seu caso de uso em linguagem simples\n\nSeja específico e fácil de entender. Explique quem você e-maila, por que e-maila, como obteve os endereços e como os destinatários podem optar por sair.\n\nOs pedidos mais fortes normalmente cobrem:\n\n- Público: quem você e-maila (por exemplo, prospects B2B que batem no seu ICP)\n- Origem: como os endereços foram obtidos (pesquisa manual, provedor verificado, seus próprios cadastros)\n- Opt-out: como as pessoas param de receber (link ou “responda stop”) e quão rápido você honra isso\n\n- Ramp: como você vai começar pequeno e aumentar gradualmente\n- Higiene: o que faz com bounces e reclamações\n\n### 3) Forneça o que a AWS normalmente pede\n\nEspere perguntas como exemplos de linhas de assunto e conteúdo, identidade da empresa, seu site e como evita mensagens enganosas. Eles frequentemente perguntam exatamente como você trata hard bounces, reclamações e pedidos de unsubscribe.\n\n### 4) Se você for rejeitado ou receber perguntas de follow-up\n\nNão reenvie o mesmo texto. Atenda à preocupação específica (geralmente qualidade da lista, clareza do opt-out ou caso de uso pouco claro). Se necessário, peça um limite menor primeiro e aumente depois que tiver métricas estáveis.\n\n## Planeje suas cotas para não bater no teto\n\nIr do AWS SES sandbox para produção é só metade do trabalho. A outra metade é garantir que seu plano de outreach caiba nas cotas do SES.\n\nVolume outbound não é “leads x 1 e-mail”. É prospects novos mais follow-ups numa sequência, espalhados por remetentes ativos.\n\nUma forma simples de estimar volume diário:\n\n- Conte caixas de envio ativas.\n- Multiplique pelo número de prospects novos por caixa por dia.\n- Multiplique pelo número médio de e-mails que um prospect realmente recebe (inicial + follow-ups).\n- Adicione uma folga (20–30%) para dias irregulares e tentativas.\n\nExemplo: 6 SDRs começam com 40 prospects novos cada por dia. Cada prospect recebe cerca de 3 e-mails no total ao longo do tempo. Isso dá 6 x 40 x 3 = 720 e-mails/dia. Com folga, planeje cerca de 900.\n\nConsidere também a qualidade da lista. Bounces ainda contam como envios. Se uma fonte de lista gera muitos bounces, você vai queimar cota mais rápido e ao mesmo tempo prejudicar a reputação.\n\nPara o ramp, comece mais devagar do que seu alvo mesmo que o SES dê margem. Um ramp conservador por semana costuma proteger a reputação:\n\n- Dias 1–2: 10–20% do volume alvo\n- Dias 3–4: 30–50%\n- Dias 5–7: 60–80%\n- Semana 2: mover-se em direção a 100% se as métricas permanecerem estáveis\n\nSolicite limites maiores cedo se você espera atingir sua cota nas próximas 2–4 semanas (por exemplo, vai adicionar assentos em breve ou sua sequência está prestes a chegar ao volume de follow-ups steady-state).\n\n## Monitoramento que mantém você em produção\n\nUma vez em produção, ficar lá é principalmente sobre manter seus sinais limpos e previsíveis.\n\n### Um painel simples semanal\n\nRevise um conjunto pequeno de métricas semanalmente (e diariamente durante o ramp):\n\n- Taxa de entrega\n- Taxa de hard bounce\n- Taxa de soft bounce\n- Taxa de reclamação\n- Taxa de unsubscribe\n\nSe a entrega cair enquanto bounces sobem, suspeite da qualidade da lista ou de problemas de autenticação. Se reclamações subirem, suspeite de segmentação, frequência ou copy.\n\n### Sinais de alerta precoce e o que fazer\n\nThrottling geralmente aparece após mudanças repetidas nas métricas, não por um único dia ruim. Procure padrões como aumento de bounce após upload de nova lista, ou picos de reclamação depois de mudança de texto.\n\nMantenha regras simples para não discutir na hora:\n\n- Se reclamações subirem, pause o segmento mais novo e revise segmentação e mensagem.\n- Se hard bounces subirem, pare a fonte daquela lista e limpe os dados antes de retomar.\n- Se soft bounces permanecerem elevados por vários dias, desacelere o ramp até estabilizar.\n\nUm changelog curto ajuda muito. Registre mudanças maiores (novo domínio, nova fonte de lista, nova série de assuntos, aumento de volume). Quando as métricas mudarem, você saberá o que provavelmente causou.\n\n## Tratamento de bounce, reclamação e unsubscribe para outbound\n\nDepois de sair do sandbox para produção, a maneira mais rápida de perder ritmo é ignorar bounces, reclamações e unsubscribes. O SES observa essas taxas de perto, e provedores de caixa também.\n\n### Bounces: hard vs soft\n\nHard bounces são falhas permanentes (caixa não existe, domínio inválido). Suprima imediatamente e nunca tente reenviar.\n\nSoft bounces são geralmente temporários (caixa cheia, erro temporário, limitação). Reenvie com cautela. Se o mesmo endereço soft bouncear repetidamente, suprima-o.\n\nUma regra segura:\n\n- Hard bounce: suprimir permanentemente.\n- Soft bounce repetido: suprimir após algumas tentativas falhas.\n- Pico súbito de bounces: pause e diagnostique antes de continuar.\n\n### Reclamações e unsubscribes\n\nReclamações (“Report spam”) são um sinal negativo forte. A melhor prevenção é segmentação rigorosa e expectativas claras, não frases espertas.\n\nUnsubscribes são normais em outbound. Trate-os como mandatórios. Se alguém opta por sair, suprima essa pessoa imediatamente em todas as sequências e listas.\n\n## Erros comuns que disparam throttling ou bloqueios\n\nMuitas equipes são aprovadas e depois encontram problemas porque a primeira semana não combina com o que descreveram para a AWS.\n\nOs padrões que mais frequentemente causam throttling:\n\n- Aumentar volume rápido demais logo após a aprovação\n- Usar fontes de lista fracas (velhas, raspadas, não verificadas)\n- Mudar muitas variáveis durante o ramp (domínio, oferta, público e volume tudo ao mesmo tempo)\n- Deixar sinais negativos se acumularem (opt-outs lentos, bounces repetidos)\n- Misturar outbound frio com e-mails transacionais importantes no mesmo domínio ou identidade\n\nPara ficar seguro, mude uma coisa de cada vez, faça ramp previsível e mantenha outbound separado de e-mail transacional.\n\n## Exemplo: migrando um pequeno time de outbound para produção SES\n\nConsidere um time de 3 SDRs rodando uma sequência de 14 dias. Cada SDR adiciona 25 prospects novos por dia. Se a sequência média tiver cerca de 4 e-mails por prospect, a matemática steady-state fica assim:\n\n- Prospects novos por dia: 3 x 25 = 75\n- E-mails médios por prospect: 4\n- Envíos diários esperados em steady state: 75 x 4 = 300 e-mails/dia\n\nNão vai começar com 300 no dia um. Follow-ups se acumulam com o tempo, então o volume cresce conforme a sequência “carrega”. Por isso seu plano de produção deve incluir um ramp, não apenas um interruptor.\n\nUm ramp realista pode ser:\n\n- Dias 1–2: limite em 60–80/dia total\n- Dias 3–4: 120–160/dia\n- Dias 5–7: 200–250/dia\n- Semana 2: aproximar-se do steady state (cerca de 300/dia)\n\nSe reclamações subirem no meio do ramp (por exemplo, 2 reclamações em 150 envios), não force. Congele o crescimento por 48 horas, corte o volume em 30–50%, ajuste segmentação e copy, e confirme que o opt-out está funcionando.\n\n## Checklist rápido e próximos passos\n\nA maioria dos problemas “AWS SES sandbox para produção” vem de fundamentos ausentes que aparecem depois como bounces, reclamações ou throttling.\n\nVerificação rápida de 5 minutos:\n\n- Acesso à produção aprovado e identidade do domínio From verificada.\n- SPF, DKIM e DMARC publicados e alinhados com o domínio From.\n- Plano de ramp existe (limites diários e aumentos graduais) que caiba nas cotas do SES.\n- Monitoramento em funcionamento, com um responsável nomeado.\n- Bounces, reclamações e unsubscribes são suprimidos imediatamente.\n\nSe quiser respostas mais rápidas quando a AWS pedir follow-ups (ou quando as métricas caírem), documente internamente três coisas: a fonte da lista, seu plano de ramp e sua regra exata de opt-out.\n\nUm próximo passo prático é um ensaio de produção de uma semana: um domínio, uma pequena pool de caixas, um segmento fechado de leads recentes e limites conservadores. Se os sinais permanecerem limpos, aumente. Se não, pause, corrija a causa e retome mais devagar.
Perguntas Frequentes
Por que o Amazon SES começa no sandbox, e por que isso é um problema para outbound?
O sandbox do SES é um modo de segurança. Ele limita volume diário e velocidade de envio, e exige que você envie apenas para destinatários verificados — o que torna outreach frio real impossível até obter acesso à produção.
O que significa na prática “apenas destinatários verificados” no sandbox do SES?
No sandbox, o SES só entrega para identidades que você verificou, como um endereço de e-mail específico ou um domínio que você controla. Prospects não são verificados, então seus envios falham mesmo que templates e sequências funcionem em testes internos.
O que muda quando o SES sai do sandbox e vai para produção?
Você pode enviar para qualquer pessoa sem verificar cada destinatário, e suas cotas são maiores do que no sandbox. Ainda assim você fica sujeito a limites diários e throttling por segundo, e taxas de bounce/reclamação começam a influenciar sua capacidade de escalar.
O que devo configurar antes de pedir acesso à produção do SES?
Configure um domínio dedicado de envio e publique SPF, DKIM e DMARC para que o domínio do From esteja alinhado com a autenticação. Garanta que o endereço From possa receber respostas, mantenha a identidade consistente e tenha um processo de unsubscribe claro e aplicado imediatamente.
O que devo escrever no pedido de acesso à produção do AWS SES para outreach frio?
Explique quem você e-maila, por que essas pessoas podem razoavelmente esperar sua mensagem, como obteve os endereços e como funcionam os opt-outs. Inclua um plano de ramp realista e descreva como trata bounces, reclamações e cancelamentos — a AWS quer ver que você vai enviar de forma responsável.
Quais métricas a AWS mais considera depois que sou aprovado?
Eles costumam olhar principalmente a taxa de bounce e a taxa de reclamação, que são os sinais mais claros sobre qualidade da lista e experiência do destinatário. Também querem ver um tratamento simples de opt-outs e mensagens não enganosas para que as pessoas possam parar de receber mensagens facilmente.
Como calculo os limites de envio que realmente vou precisar?
Estime o total de envios, não apenas leads novos, porque follow-ups se acumulam numa sequência. Multiplique caixas ativas por novos prospects por caixa/dia e pelo número médio de e-mails que cada prospect recebe na sequência, depois acrescente uma margem para não bater no limite no meio da semana.
Com que rapidez devo aumentar o volume depois de ir para produção?
Comece abaixo do volume alvo mesmo que o SES te dê mais espaço, e aumente gradualmente desde que bounces e reclamações se mantenham estáveis. Se você sobe rápido demais, pode disparar throttling, fazer follow-ups atrasarem e prejudicar sinais iniciais de reputação.
Qual a forma mais segura de tratar bounces, reclamações e unsubscribes no SES?
Suprima imediatamente hard bounces e não tente reenviar para eles, pois falhas repetidas desperdiçam cota e prejudicam métricas. Honre unsubscribes na hora e em todas as sequências e listas, e trate reclamações como um sinal para pausar e investigar segmentação, texto e frequência.
Como evito throttling ou bloqueios depois de obter acesso à produção?
Mude uma coisa por vez e mantenha um registro simples do que foi alterado — fonte da lista, copy, domínio ou volume. Se suas operações estiverem espalhadas por muitas ferramentas, um sistema unificado como o LeadTrain pode ajudar a manter domínios, warm-up, sequências e classificação de respostas consistentes durante o ramp-up.