Tests A/B d'offres : un plan clair au-delà des lignes d'objet
Apprenez une méthode pratique pour tester des offres en A/B : contrôler les variables, choisir des tailles d'échantillon honnêtes et interpréter les résultats sans conclusions hâtives.
Pourquoi les tests d'offres A/B donnent souvent des résultats confus
Les tests d'offres dans l'outbound à froid semblent souvent aléatoires parce que la boîte de réception est un endroit chaotique. Ce n'est pas un laboratoire. Vous testez auprès de personnes occupées, de priorités changeantes, de filtres anti‑spam et de listes de prospects jamais parfaitement équivalentes.
Une raison fréquente pour laquelle les résultats paraissent confus : on dit tester l'offre, mais on change discrètement aussi le texte. Si une version est plus courte, plus claire, plus assurée ou comporte un appel à l'action plus fort, vous n'apprenez plus sur l'offre. Vous apprenez sur l'écriture.
Même quand vous essayez d'isoler l'offre, celle‑ci est liée au contexte. Un « audit gratuit » peut sembler précieux pour un segment et être perçu comme du travail en plus pour un autre. Si vos deux variantes finissent par être envoyées à des intitulés de poste, tailles d'entreprise ou secteurs différents, les résultats basculent et vous blâmez l'offre.
La plupart des « gagnants dramatiques » ne sont que du bruit qui se manifeste comme :
- Des variations semaine après semaine parce que les prospects étaient différents, pas parce que l'offre était meilleure.
- Des échantillons petits où quelques réponses en plus créent un faux gagnant.
- Des variations de délivrabilité (nouveaux domaines, problèmes de warm‑up, changements d'authentification) qui modifient qui voit réellement l'email.
- Des effets de timing comme les jours fériés, la fin de trimestre ou un cycle d'actualité sectoriel.
- Une gestion des réponses inconsistante, où une version obtient plus de « pas maintenant » et vous comptez ça comme un succès.
Un scénario courant : vous lancez un test d'offre, la Variante B obtient 6 réponses le lundi et vous la déclarez gagnante. Puis vous réalisez que ces réponses étaient surtout des messages d'absence du bureau et des reports polis, et que le reste de la semaine c'est le calme plat. Ce n'était pas de la magie. C'était de la variance.
L'objectif n'est pas la certitude. Un test d'offre propre réduit l'incertitude pour que vous puissiez prendre une meilleure décision. Si vous traitez chaque test comme une pièce de preuve, pas comme un verdict final, vous arrêtez de courir après des faux gagnants et vous commencez à construire des offres qui tiennent dans la durée.
Ce qui compte comme offre (et ce qui n'en fait pas partie)
Quand on dit vouloir tester des offres, on entend souvent « changer l'email et voir ce qui se passe ». Cela mélange généralement trop de variables. Commencez par définir l'offre.
Une offre est l'échange que vous proposez : ce que vous demandez au lecteur, ce qu'il obtient en retour, et pourquoi c'est pertinent maintenant.
Les éléments qui font partie de l'offre
Pensez l'offre comme un petit paquet. Changer l'un de ces éléments change l'offre :
- CTA (la demande) : « Répondez OUI », « Choisissez un créneau », « Envoyez‑moi le contact approprié », « Vous voulez que je regarde ? »
- Angle de valeur (la promesse) : gagner du temps, réduire les coûts, obtenir plus de leads, corriger la délivrabilité, améliorer la conversion
- Incitation : audit gratuit, pack de templates, rapport benchmark, carte cadeau, période d'essai prolongée
- Niveau d'engagement : « répondez avec un chiffre » vs appel de 5 minutes vs démo de 30 minutes
- Timing/urgence : « cette semaine », « avant la fin du mois », « tant qu'il nous reste 3 créneaux »
Exemples concrets de variantes d'offre réelles :
- « Audit gratuit de 10 minutes de vos e‑mails outbound » vs « Démo produit de 15 minutes »
- « Essai gratuit de 7 jours » vs « Une page d'étude de cas personnalisée pour votre entreprise »
- « Je vous envoie une liste de quick wins » vs « Je construis un mini plan pour votre prochaine séquence »
Ce qui n'est pas l'offre
Ces éléments peuvent beaucoup faire varier les résultats, mais ce sont des tests séparés :
- Ligne d'objet et texte d'aperçu
- Nom de l'expéditeur, adresse d'envoi, style de signature
- Facteurs de délivrabilité : ancienneté du domaine, warm‑up de la boîte, placement en spam
- Mix d'audience : secteur, niveau hiérarchique, source des leads
- Timing d'envoi : jour de la semaine, heure
Si votre but est de savoir quelle offre fonctionne, gardez les éléments non‑offre stables et ne changez que l'échange que vous proposez.
Choisissez une métrique principale mesurable proprement
Si vous voulez tester des offres (et pas seulement des lignes d'objet), choisissez une métrique de succès principale. Une suffit. Avoir plusieurs « principales » invite au cherry‑picking a posteriori.
Choisissez la métrique qui correspond au résultat que vous voulez vraiment :
- Taux de réponses positives : toute réponse humaine qui n'est pas un bounce ou un désabonnement
- Taux d'intérêt qualifié : réponses montrant un vrai cas d'usage, pas juste « envoyez les infos »
- Taux de réunions réservées : le résultat business le plus net, mais plus long à mesurer
- Coût par réponse qualifiée : si vous suivez les dépenses par source de leads
Quelle que soit la métrique, définissez des labels pour que chaque réponse soit comptée de la même façon. Écrivez les règles avant de commencer. Par exemple :
- « Intéressé » = pose des questions sur le prix, le calendrier, la pertinence ou les étapes suivantes
- « Pas intéressé » = refus clair
- « Absence » = message automatique de report sans engagement
Définissez aussi votre fenêtre de réponse à l'avance. Une règle pratique pour l'email à froid est de compter les réponses arrivées dans les 7 à 10 jours après le premier envoi (ou 7 à 10 jours après chaque étape si vous comparez des offres dans une séquence). Les réponses tardives ajoutent du bruit et favorisent la variante qui a couru plus longtemps.
Évitez d'utiliser les ouvertures et les clics comme métrique principale. Les ouvertures sont gonflées par les fonctions de confidentialité, et les clics peuvent refléter la curiosité plutôt que l'intention.
Comment isoler l'offre et garder tout le reste stable
Les tests d'offre propres échouent pour une raison simple : deux choses changent à la fois. Si vous voulez que vos résultats aient du sens, il doit y avoir une différence claire entre A et B, et tout le reste doit être ennuyeusement constant.
Gardez le contexte fixe
Verrouillez le contexte avant d'écrire une seule ligne. Les mêmes personnes doivent recevoir A et B de la même façon, pendant la même fenêtre. Sinon, vous testez la qualité de la liste, le timing ou la délivrabilité.
Gardez constants :
- Source et filtres de la liste : même fournisseur, mêmes intitulés, même taille d'entreprises
- Persona et cas d'usage : ne mélangez pas fondateurs et responsables marketing dans un même test
- Structure de la séquence : mêmes étapes, mêmes délais, même logique de relance
- Calendrier d'envoi : mêmes jours, mêmes heures, mêmes limites de volume quotidien
- Configuration de délivrabilité : même domaine d'envoi et santé de la boîte mail
Alignez aussi la structure de l'email. Si l'offre A compte deux phrases courtes et l'offre B un long paragraphe avec plus de preuves, vous avez changé plus que l'offre. Gardez le format aligné : longueur similaire, nombre de lignes similaire, même forme de CTA.
Changez une chose exprès
Définissez chaque offre en une phrase, puis éditez seulement le texte minimum nécessaire pour refléter l'échange.
Exemple :
- Offre A : « Audit de 15 minutes avec 3 corrections »
- Offre B : « Pack de templates gratuit plus une courte session de walkthrough »
Gardez l'accroche, la douleur et le ton identiques. Ne changez que l'échange.
Si vous découvrez un problème non lié en cours de test (champ de personnalisation cassé, pic de bounce, problème de domaine), ne réparez pas à la va‑vite et ne continuez pas. Mettez en pause, corrigez, puis relancez avec une nouvelle répartition et une note sur ce qui a changé. Sinon, vous mélangerez « impact de l'offre » et « impact de l'incident ».
Étape par étape : monter le test de l'idée au lancement
Commencez par formuler chaque offre assez simplement pour la dire en une phrase. Si vous n'y arrivez pas, vous ne pouvez pas la tester.
Écrivez deux offres qui diffèrent par la valeur, pas seulement par la formulation. Par exemple :
- « Audit gratuit de 10 minutes de vos e‑mails outbound »
- « Je vous envoie un plan en 3 slides pour obtenir 10 réunions qualifiées ce mois »
Puis construisez deux versions de la même séquence. Gardez la structure identique : même nombre d'étapes, mêmes jours d'envoi, même approche de personnalisation, même format de CTA. Ne changez que la ou les lignes présentant la valeur.
Plan de construction simple :
- Rédigez l'Offre A et l'Offre B en une phrase chacune.
- Dupliquez la séquence et ne changez que la ou les phrases liées à l'offre.
- Utilisez la même définition d'audience et la même source de liste.
- Répartissez les prospects 50/50 au hasard pour que chaque variante voie des personnes comparables.
- Faites tourner les deux variantes en même temps.
Fixez vos règles avant l'envoi :
- Règle d'arrêt : une date de fin fixe ou une taille d'échantillon livrée fixe par variante.
- Métrique de succès : la métrique principale que vous avez choisie.
- Étiquettes de réponses : les définitions que vous utiliserez.
Avant le lancement, faites une dernière vérification de bon sens :
- Les deux versions demandent le même type de réponse.
- La seule vraie différence est l'offre.
- La répartition est aléatoire et simultanée.
- La règle d'arrêt est écrite et ne changera pas en cours de route.
Taille d'échantillon et durée pour garder les résultats honnêtes
Les petits tests aiment mentir. Avec seulement quelques réponses, une réponse en plus (ou une réponse rageuse) peut faire varier vos taux de 50 % ou plus.
Nombres pratiques qui tiennent la route
Si possible, visez 300 à 500 prospects livrés par variante. C'est souvent suffisant pour qu'une poignée de réponses aléatoires ne sacre pas un faux gagnant.
Si vous ne pouvez pas atteindre ce volume :
- Ne prétendez pas mesurer de petites différences.
- Ne faites confiance qu'à de grands écarts (par exemple, une offre obtenant environ 2x plus de réponses positives).
- Limitez‑vous à deux variantes. Plus de versions dispersent trop votre volume.
La durée compte autant que le volume. La performance des emails à froid varie selon le jour de la semaine, les jours fériés et la fatigue des boîtes de réception. Si vous faites tourner un test pendant deux jours, vous risquez de mesurer lundi vs mercredi plutôt qu'Offre A vs Offre B.
Une durée minimale plus sûre est 7 jours complets. Pour des audiences lentes à répondre (entreprises, fondateurs, profils très occupés), 10 à 14 jours est souvent plus réaliste.
Le plus grand piège est le « peek ». Si vous regardez les résultats tous les jours et arrêtez dès qu'une offre paraît devant, vous sélectionnez le gagnant au moment le plus bruyant.
Choisissez une règle d'arrêt et tenez‑vous y :
- Date de fin fixe (ex. : 14 jours), ou
- Taille d'échantillon livrée fixe (ex. : 400 livrés par variante)
Si le volume est faible, ajustez le plan au lieu de forcer un « résultat propre ». Faites durer plus longtemps, testez moins de choses à la fois, et acceptez que vous cherchez des victoires évidentes, pas des gains de 5 %.
Comment lire les résultats sans sur‑réagir
Commencez par la métrique principale choisie avant l'envoi. Si l'objectif était « réponses intéressées », comparez d'abord cela et ignorez le reste un moment. Mélanger d'autres métriques est la façon de se convaincre d'un gagnant qui n'est pas réel.
Séparez ensuite impact et confiance :
- Un effet peut être réel mais trop faible pour être utile (2,0 % vs 2,3 % de réponses intéressées peut ne rien changer au pipeline).
- Une grosse hausse sur un petit échantillon peut rester instable.
Avant de déclarer un gagnant, vérifiez que les deux groupes étaient vraiment similaires. Une distribution inégale crée de faux gains, surtout si une variante a reçu plus de titres seniors ou plus d'un secteur performant.
Vérifications rapides de bon sens :
- Répartition de l'audience : intitulés, taille d'entreprise, secteur, région
- Timing : une variante est‑elle tombée pendant une semaine de congés ou des jours différents ?
- Signaux de délivrabilité : bounces et plaintes spam
- Composition des réponses, pas seulement le nombre
La composition des réponses compte parce que « plus de réponses » peut signifier « plus d'objections ». Si possible, passez les réponses en revue par catégorie (intéressé, pas intéressé, absence, désabonnement). Une variante qui augmente les « pas intéressé » peut simplement être plus claire, pas meilleure.
Quand vous clôturez le test, rédigez une courte note de décision :
- Ce que vous croyez pour l'instant (basé sur la métrique principale)
- Ce que vous ignorez encore (taille de l'échantillon, biais, timing)
- Ce que vous ferez ensuite (déployer, relancer, ou resserrer la variation)
Cela maintient l'expérimentation calme et reproductible quand les chiffres sont proches.
Erreurs fréquentes qui créent des conclusions bruitées
La plupart des tests « ratés » n'ont pas échoué parce que l'offre était mauvaise. Ils ont échoué parce que le test a mélangé des signaux.
La principale erreur : changer plus que l'offre. Si vous ajustez l'offre, la ligne d'objet et l'audience en même temps, le résultat est une bouillie.
Les différences de délivrabilité sont le tueur silencieux. Si la Variante A sort depuis une configuration chauffée et la Variante B depuis un domaine ou une boîte récente ou modifiée, vous ne testez pas l'offre. Vous testez le placement en boîte de réception. Verrouillez votre configuration d'envoi durant le test.
La dérive des relances est un autre classique. Vous séparez proprement l'Email 1, puis quelqu'un édite la relance #2 pour une seule version ou change le CTA. Maintenant vous comparez deux séquences différentes, pas deux offres.
Autres sources communes de bruit :
- Mélanger les audiences de façon à ce qu'une variante obtienne des leads plus propres ou des comptes plus gros
- Envoyer à des jours différents ou à des volumes très différents
- Mettre en pause une variante en cours de route après des « bons » résultats précoces
- Déclarer gagnant parce qu'un gros compte a répondu (les outliers faussent les petits échantillons)
- Compter les « réponses » sans séparer intéressé et pas intéressé
Checklist rapide avant le lancement
Avant d'appuyer sur envoyer, assurez‑vous que vous testez vraiment l'offre, pas un tas de petits changements.
- Une seule différence d'offre. Choisissez la modification unique (audit vs démo, essai gratuit vs rapport, CTA à faible friction vs prise de RDV). Gardez le reste aussi proche que possible.
- Mêmes règles d'audience, même source de liste. Même source et mêmes filtres pour les deux variantes.
- Même séquence et calendrier. Mêmes étapes, mêmes timings, mêmes jours et mêmes volumes.
- Règle d'arrêt écrite. Décidez de la date de fin ou de la taille d'échantillon livrée avant le lancement.
- Étiquettes de réponses claires. Définissez ce qui compte comme positif et comme qualifié, y compris les cas limites comme « pas maintenant ».
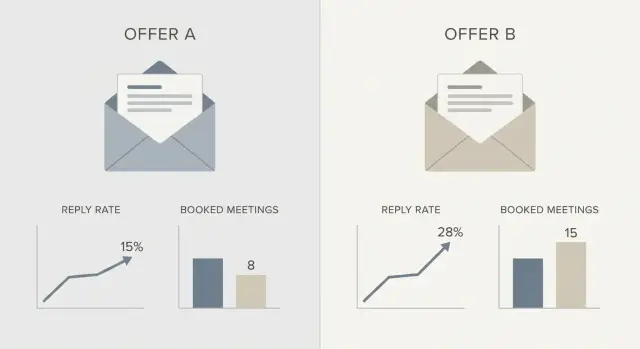
Exemple : tester deux offres dans une séquence d'email à froid
Un SDR contacte des responsables financiers (VP Finance, Contrôleur, Responsable FP&A) dans des entreprises SaaS de taille intermédiaire. Le but est d'apprendre quelle offre génère le plus d'intérêt réel, pas quelle ligne d'objet obtient le plus d'ouvertures.
Deux offres :
- Offre A : un teardown de 15 minutes de leurs e‑mails outbound, suivi de 3 corrections concrètes à appliquer.
- Offre B : un bref rapport benchmark les comparant à des équipes SaaS similaires, suivi d'un appel de revue de 10 minutes.
Pour isoler l'offre, tout le reste reste identique : filtres d'audience, configuration d'envoi et structure d'email. Seul l'échange change.
Gardez constants pour les deux variantes :
- Règles de la liste de leads (rôle, taille d'entreprise, secteur, géographie)
- Squelette du texte (ligne d'ouverture, ligne de crédibilité, format du CTA, longueur)
- Méthode de personnalisation (une phrase basée sur le rôle ou la stack tech)
- Cadence des relances (mêmes étapes, mêmes délais, mêmes jours d'envoi)
- Identités d'expéditeurs et santé des domaines
Répartissez les prospects 50/50 au démarrage de la séquence et lancez les deux en même temps.
Décidez du gagnant avec deux chiffres défendables :
- Primaire : taux d'intérêt (réponses intéressées / emails livrés)
- Secondaire : réunions réservées, considérées comme un retour plus lent
Si l'Offre A a un taux d'intérêt supérieur et mène au moins au même nombre de réunions réservées après la même période, conservez‑la et itérez. Si une offre reçoit plus de réponses mais que la plupart sont des « pas intéressé », elle attire probablement le mauvais type d'attention.
Étapes suivantes : itérer calmement et faciliter les tests
Une fois que vous avez un gagnant, traitez‑le comme un nouveau défaut, pas comme un trophée. Faites de cette offre la base pour le prochain cycle, puis changez un seul angle d'offre à la fois.
Tenez un journal d'expérimentations simple pour ne pas répéter les tests ou mal vous rappeler des résultats :
- Hypothèse
- Règles d'audience
- Dates et taille d'échantillon
- Résultats (métrique principale + notes courtes)
- Décision (conserver, revenir en arrière, retester)
Avant de juger une offre, confirmez que la délivrabilité est stable. Si le placement en boîte vacille parce qu'une boîte est nouvelle, que le warm‑up a été interrompu ou que l'authentification a changé, corrigez cela d'abord.
Si la mesure cohérente est un goulot d'étranglement pour votre équipe, une plateforme tout‑en‑un peut aider en centralisant la configuration et le suivi. Par exemple, LeadTrain (leadtrain.app) combine domaines, warm‑up, séquences multi‑étapes et classification des réponses (intéressé, pas intéressé, absence, bounce, désabonnement) pour comparer les variantes sans trop de tri manuel.
Quand vous décidez quoi tester ensuite, choisissez le plus petit changement d'offre qui répond à une vraie question. Si votre gagnant actuel obtient des réponses mais peu de réunions, testez le niveau d'engagement plutôt que de réécrire tout le pitch : CTA à moindre friction vs prise de RDV, audit vs appel de 10 minutes, ou la même offre avec une preuve différente.
Avancez pas à pas. Un apprentissage régulier vaut mieux qu'un mouvement permanent.
FAQ
Pourquoi les tests A/B d'offres dans l'email à froid semblent-ils si incohérents ?
Les tests d'offres semblent aléatoires quand plus que l'offre change ou quand A et B touchent des types de prospects différents. Gardez l'audience, le timing, la structure des séquences et la configuration d'envoi identiques pour que la seule différence significative soit l'échange que vous proposez.
Qu'est‑ce qui compte exactement comme « offre » dans un email à froid ?
L'offre est l'échange : ce que vous demandez au lecteur, ce qu'il reçoit en retour, et pourquoi c'est pertinent maintenant. Changer le CTA, l'incitation, le niveau d'engagement ou l'urgence revient à changer l'offre, même si le reste de l'email reste identique.
Quels changements ne font pas partie d'un test d'offre, même s'ils font bouger les chiffres ?
Les lignes d'objet, le nom de l'expéditeur, la longueur de l'email, le ton, les preuves, le timing et la délivrabilité ne font pas partie de l'offre, même s'ils influencent fortement les résultats. Si vous les modifiez en testant l'offre, vous étudierez l'écriture ou le placement en boîte de réception, pas l'offre elle‑même.
Quelle est la meilleure métrique de succès pour un test d'offre ?
Choisissez une métrique principale qui correspond à ce que vous voulez vraiment. Pour la plupart des équipes, « intérêt qualifié » ou « réunions réservées » est plus utile que le taux brut de réponses, car cela réduit le risque de récompenser des réponses vides ou négatives.
Comment dois‑je étiqueter les réponses pour éviter de fausser les résultats ?
Rédigez des règles d'étiquetage simples avant l'envoi, puis appliquez‑les de la même façon à chaque réponse. Décidez à l'avance si absence, « pas maintenant » ou « envoyer des infos » compte comme succès, afin de ne pas couronner un gagnant sur une notation incohérente.
Comment m'assurer que la variante A et la variante B atteignent des prospects comparables ?
Lancez les deux variantes en même temps, répartissez les prospects au hasard 50/50 et utilisez la même source de liste et les mêmes filtres. Si une variante obtient plus de profils seniors ou un segment plus propre, vous testez le mix de la liste, pas l'offre.
Combien d'e-mails me faut‑il par variante pour pouvoir faire confiance au résultat ?
Visez environ 300 à 500 prospects livrés par variante si possible, car les petits échantillons varient énormément. Si vous êtes en dessous, ne faites confiance qu'à de grands écarts et évitez plusieurs variantes qui diluent votre volume.
Combien de temps dois‑je faire tourner un test d'offre avant de décider ?
Comptez les réponses dans une fenêtre fixe comme 7 à 10 jours après le premier envoi, et laissez la période totale assez longue pour couvrir la variation jour‑par‑jour normale. Ne vous arrêtez pas tôt parce qu'une version semble en tête un lundi ; c'est souvent du bruit.
Que faire si la délivrabilité ou le texte change en cours de test ?
Mettez en pause et relancez si quelque chose de fondamental change, comme un problème de délivrabilité, un champ de personnalisation cassé, ou des modifications des relances sur une seule variante. Si vous réparez en cours de route et continuez, vous mélangerez l'impact de l'offre avec l'impact de l'incident et vous ne saurez pas ce qui a causé le changement.
Comment LeadTrain peut‑il m'aider à exécuter des tests A/B d'offres plus propres ?
Utilisez un flux de travail qui stabilise la configuration d'envoi, impose des séquences identiques et applique des catégories de réponses cohérentes entre variantes. LeadTrain est conçu autour de cette idée : il combine domaines, boîtes mail, warm‑up, séquences et classification automatique des réponses (intéressé, pas intéressé, absence, bounce, désabonnement) dans un même endroit pour comparer les variantes sans beaucoup de tri manuel.