Pipeline d'événements de rebond et de plainte SES pour des listes propres
Construisez un pipeline d'événements de rebond et de plainte SES pour stocker les événements, supprimer automatiquement les adresses à risque et conserver une piste d'audit fiable pour votre équipe.
Pourquoi vous avez besoin d'un pipeline de rebonds et plaintes
Un rebond se produit lorsqu'un email ne peut pas être délivré. Parfois c'est permanent (l'adresse n'existe pas). Parfois c'est temporaire (la boîte est pleine, le serveur est occupé, ou le fournisseur vous bride). Une plainte survient lorsqu'un destinataire marque votre email comme spam ou le signale comme indésirable. Les deux sont des signaux clairs pour arrêter d'envoyer à cette adresse, ou au moins faire une pause et enquêter.
Ignorer ces signaux fait vite baisser la délivrabilité. Les fournisseurs de messagerie apprennent que vos messages créent des problèmes, et davantage d'emails futurs atterrissent en spam — même auprès de bons leads. Vous gaspillez aussi de l'argent en envoyant à des adresses mortes et du temps à courir après des personnes qui n'ont jamais vu votre message.
Un pipeline d'événements de rebond et de plainte n'est pas une question d'analytique sophistiquée. C'est un système petit et fiable qui :
- capture chaque événement de rebond et de plainte
- supprime vite les adresses problématiques
- conserve une piste d'audit consultable
La dernière partie est facile à sous-estimer. Une semaine plus tard, quelqu'un demandera : « Est-ce qu'on a vraiment contacté cette personne ? » ou « Pourquoi cette adresse a-t-elle été supprimée ? » Si vous ne conservez qu'un simple drapeau de suppression sans historique, vous ne pourrez pas répondre en toute confiance.
La configuration ci-dessous utilise des blocs AWS courants (SNS, SQS, Lambda) pour capturer les événements, les traiter en sécurité et les stocker. Elle ne couvre pas la rédaction des messages, la source des listes, les domaines d'envoi ni la configuration complète de SES.
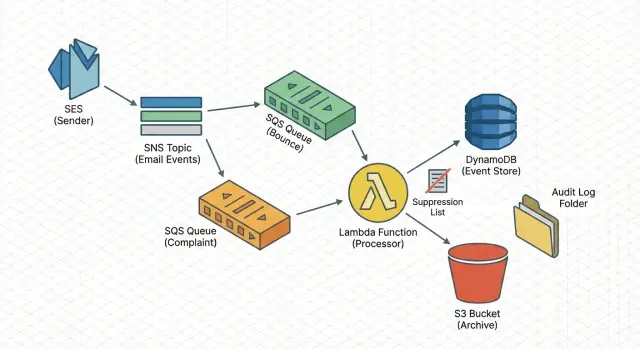
L'architecture simple en un coup d'œil
Un pipeline fiable doit être ennuyeux : chaque événement atterrit quelque part de sûr, est traité de façon reproductible, et laisse un enregistrement que vous pouvez consulter plus tard.
Le flux (ingestion -> file -> traitement)
Un chemin éprouvé est :
SES envoie les notifications de rebond/plainte à SNS, SNS livre à SQS, et un worker Lambda lit depuis SQS.
Cette approche absorbe les pics, survit aux brèves pannes et vous permet de réessayer sans bloquer vos envois.
Ce que fait le worker
Limitez la Lambda à l'essentiel. Elle doit valider, normaliser, écrire l'événement, puis appliquer des effets secondaires (comme la suppression). Étapes typiques :
- valider le payload (JSON malformé, email manquant, type manquant)
- dédupliquer en utilisant un ID d'événement ou une clé stable comme
message_id + recipient_email + event_type - classifier l'événement (hard bounce, soft bounce, plainte)
- appliquer une action simple (supprimer, avertir seulement, ignorer)
- attacher du contexte (domaine d'envoi, boîte mail, ID de campagne)
Stockage + actions (recherche rapide et audit)
Utilisez deux couches de stockage : une optimisée pour les requêtes rapides et une pour la preuve à long terme. Par exemple :
- un enregistrement « statut le plus récent par adresse » pour les recherches rapides
- une archive du payload brut pour les audits et le débogage
Depuis le même worker, vous pouvez aussi déclencher des actions : ajouter l'adresse à une liste de suppression, alerter quand le taux de plaintes augmente, et taguer la campagne pour tracer quel message a posé problème. C'est le même schéma général que des outils comme LeadTrain utilisent pour maintenir la délivrabilité propre quand ils envoient via des setups SES séparés.
Configurer SES pour publier les événements de rebond et de plainte
D'abord, assurez-vous que SES émette les bons signaux chaque fois qu'un email échoue ou qu'un destinataire se plaint.
Dans SES, créez un configuration set (ou réutilisez-en un que vous attachez déjà aux mails sortants) et activez la publication d'événements pour Bounce et Complaint. Conservez le payload aussi proche du brut que possible. Vous voudrez des détails plus tard : horodatage, message ID, adresse de destination, type de rebond et feedback de plainte.
Traitez les environnements séparément. Utilisez un topic SNS pour la production et un autre pour le staging afin que l'activité de test ne pollue pas les métriques réelles.
Une configuration simple :
- Créez un topic SNS par environnement (par exemple ses-events-prod et ses-events-staging).
- Dans votre configuration set, publiez les événements Bounce et Complaint vers le topic SNS correspondant.
- Abonnez des files SQS au topic SNS. Beaucoup d'équipes utilisent une file opérationnelle pour la suppression/alertes et une file séparée pour le reporting.
- Verrouillez la policy de chaque file SQS pour que seul votre topic SNS puisse envoyer des messages (restreindre par SourceArn et compte).
- Envoyez un petit lot de test et confirmez que vous recevez bien les messages de rebond et de plainte avec les champs attendus.
Bufferiser les événements en toute sécurité avec SQS
SQS est le tampon de sécurité entre les événements SES et votre code. Il découple le système pour qu'un pic de rebonds ou de plaintes n'écrase pas votre worker. Si Lambda est hors service quelques minutes, les événements attendent dans la file au lieu de disparaître.
Pour la plupart des pipelines, une file Standard est le choix le plus simple. Elle peut livrer des messages plus d'une fois, donc le worker doit être idempotent (sûr à exécuter deux fois). Choisissez FIFO seulement si vous avez réellement besoin d'un ordre strict ou d'une déduplication au niveau de la file.
FIFO vs Standard en clair
FIFO peut être pertinent si vous avez besoin :
- d'un ordre strict pour la même adresse email
- de la déduplication au niveau de la file
- d'un volume prévisible, plus faible, qui ne bute pas sur les limites FIFO
Dead-letter queue et limites de retry
Utilisez une dead-letter queue (DLQ) pour que les messages poison n'empêchent pas le trafic sain. Un point de départ sûr :
- max receives : 5 à 10
- rétention des messages : assez longue pour enquêter (quelques jours est courant)
- alarmes lorsque la profondeur de la DLQ est supérieure à 0
Gardez les messages petits, mais ne jetez pas le contexte. Stockez le payload SES complet (ou le corps complet du message SNS) pour pouvoir auditer plus tard. Si vous changez les règles de suppression à l'avenir, le payload original est ce qui vous permettra d'expliquer pourquoi une adresse a été supprimée.
Traiter les événements avec un petit worker Lambda
Le worker Lambda traduit les événements SES en décisions opérationnelles. Gardez la tâche étroite : parser un message, extraire quelques champs, écrire un enregistrement d'événement, et mettre à jour l'état de suppression si nécessaire.
Commencez par normaliser les payloads SES vers un schéma interne unique. Les différents types d'événements ne se ressemblent pas toujours, donc choisissez une forme cohérente et mappez-y tout. Minimum pratique :
- event_type (bounce, complaint, delivery)
- message_id (SES mail.messageId)
- recipient_email
- event_time (un horodatage cohérent)
- source (configuration set, identité d'envoi, ou nom du système)
Normalisez les types de rebond tôt. Gardez « bounce » comme type principal, et stockez hard vs soft comme champ séparé. Faites de même pour les plaintes : conservez les détails de sous-type s'ils existent, mais ne laissez pas ces détails fragmenter votre flux principal.
L'idempotence compte parce que SQS peut livrer des messages plus d'une fois. Utilisez une clé stable comme message_id + recipient_email + event_type. Avant d'écrire, vérifiez si vous avez déjà stocké cette clé. Si oui, acquittez et sortez. Cela évite la double suppression et garde les compteurs honnêtes.
Soyez strict sur les horodatages. Stockez l'horodatage de l'événement dans un format cohérent (par exemple des chaînes ISO). Stockez aussi received_at séparément pour repérer les délais.
Une bonne règle : écrivez d'abord l'enregistrement d'événement, puis appliquez les effets secondaires. Si le worker échoue après l'écriture mais avant la suppression, vous pouvez relancer la suppression plus tard sans perdre la piste d'audit.
Stocker les événements pour la rapidité et la piste d'audit
Vous voulez deux choses à la fois : des réponses rapides (« puis-je encore envoyer à cette adresse ? ») et une traçabilité complète quand quelque chose cloche.
Stockez un petit résumé que vous pouvez interroger vite, et conservez le payload AWS brut séparément. Le payload brut est votre source de vérité quand il faut expliquer un pic de plaintes ou prouver pourquoi une adresse a été supprimée.
Un enregistrement résumé peut rester compact :
- event_id (votre ID unique)
- message_id (venant de SES)
- recipient (adresse email)
- type et sous-type (bounce, complaint ; hard/soft)
- reason (texte court ou code)
Une association courante est DynamoDB pour les recherches rapides et S3 pour l'archive. DynamoDB fonctionne bien quand votre chemin d'envoi a besoin d'un check rapide « est-ce que ce destinataire a déjà bouncé ? ». S3 est peu coûteux pour stocker du JSON brut à grande échelle.
Un pattern simple : écrivez le résumé dans DynamoDB, stockez le payload brut en S3 avec une clé incluant la date et le message_id, et enregistrez cette clé S3 sur l'enregistrement DynamoDB.
La rétention est un choix de politique. Certaines équipes gardent les résumés à long terme et expirent les payloads bruts plus tôt. Si vous avez besoin d'audits profonds, faites l'inverse.
Supprimer automatiquement les adresses problématiques (règles simples)
L'auto-suppression est là où le pipeline rembourse son coût. Le but n'est pas un modèle parfait, mais d'arrêter rapidement les adresses manifestement mauvaises et de pouvoir expliquer la décision plus tard.
Commencez par des règles faciles à défendre :
- Hard bounce : suppression immédiate.
- Plainte : suppression immédiate.
- Soft bounce : suppression seulement après N événements dans une fenêtre glissante (par exemple 3 soft bounces en 7 jours).
- Désinscription (si vous la capturez séparément) : suppression immédiate.
Les soft bounces sont délicats car ils peuvent être temporaires. La règle de seuil évite de sur-réagir à une mauvaise journée tout en retirant les adresses qui échouent de façon répétée.
Maintenez une petite allowlist pour les domaines internes, boîtes de test et adresses seed. Gardez-la restreinte et revue pour qu'elle n'étouffe pas de vrais problèmes.
Chaque suppression doit être auditable. Stockez :
- la règle qui a déclenché la suppression
- les métadonnées de l'événement déclencheur (horodatage, message ID, type de rebond)
- le contexte source (ID de campagne, domaine d'envoi, boîte mail)
Cette piste rend l'automatisation plus sûre et facilite les réhabilitations quand quelqu'un dit : « Ce lead est valide, merci de le réactiver. »
Garder une liste de suppression digne de confiance
Une liste de suppression n'aide que si tout le monde la considère comme la source de vérité. Cela implique deux choses : un statut clair par destinataire, et un seul endroit que le système d'envoi vérifie avant chaque envoi.
Beaucoup d'équipes s'en sortent bien avec trois statuts :
- active : ok pour envoyer
- suppressed : ne pas envoyer
- pending-review : en pause jusqu'à confirmation humaine
Le chemin d'envoi ne doit pas deviner. Avant d'envoyer, faites une recherche et bloquez l'envoi si le statut est suppressed ou pending-review. Placez ce contrôle dans le service qui construit la liste d'envoi, pas dans un tableau de bord que l'on pourrait oublier d'utiliser.
La réactivation est source d'erreurs. Autorisez-la, mais de façon délibérée. Exigez une raison et enregistrez qui l'a approuvée. Si vous avez plusieurs outils, simplifiez : un seul système est autorisé à changer le statut de suppression, et tout le reste doit l'appeler.
Aussi, ne réécrasez pas l'historique. Chaque changement de statut doit générer un événement d'audit : quoi a changé, de quoi à quoi, quand, et ce qui l'a déclenché.
Exemple : une adresse fait un hard bounce le lundi et est supprimée automatiquement. Le jeudi, le lead répond depuis une adresse corrigée. Vous gardez l'ancienne adresse supprimée, marquez la nouvelle active, et consignez les deux changements avec des notes. Dans des plateformes comme LeadTrain, ce type d'historique aide la classification des réponses et la logique d'envoi à s'appuyer sur une décision de suppression cohérente.
Erreurs courantes et comment les éviter
Un pipeline peut sembler terminé le premier jour et produire quand même de mauvaises décisions plus tard. La plupart des problèmes viennent de petites hypothèses qui biaisent les métriques ou déclenchent de mauvaises suppressions.
Un piège est de traiter « délivré » comme « arrivé en boîte de réception ». SES peut vous dire que le serveur récepteur a accepté le message, pas où il a atterri. Utilisez la livraison comme signal de santé d'envoi, pas comme preuve d'une arrivée en inbox.
Autre problème : traiter tous les rebonds de la même façon. Un rebond transitoire ne mérite pas la même réponse qu'un rebond permanent. La sur-suppression réduit votre liste et peut masquer des problèmes réels comme le pacing, le contenu ou la réputation d'un nouveau domaine.
Erreurs courantes et correctifs :
- Pas de retries : si votre worker échoue une fois, l'événement disparaît. Correctif : SQS + retries + DLQ + traitement idempotent.
- Pas de clé de dédoublonnage : le même événement est traité deux fois. Correctif : stocker un ID d'événement unique et ignorer les répétitions.
- Suppression à chaque rebond : les problèmes temporaires deviennent des pénalités permanentes. Correctif : supprimer immédiatement sur hard bounces et plaintes ; appliquer des seuils pour les soft bounces.
- Stocker seulement des agrégats : vous ne pouvez pas répondre « pourquoi ceci a été supprimé ? ». Correctif : stocker les événements bruts avec message IDs, timestamps et la règle qui a déclenché.
- Supposer que la livraison équivaut à l'inbox : les métriques semblent bonnes alors que les réponses chutent. Correctif : séparer délivré et engagé et surveiller les taux de réponse par boîte mail et domaine.
Exemple : vous envoyez 2 000 emails et voyez 1 980 délivrés. Si 30 sont des soft bounces d'un même domaine et que vous les supprimez immédiatement, vous risquez d'éliminer des leads valides. Une meilleure règle est « supprimer seulement les hard bounces et les plaintes, et supprimer les soft bounces seulement après 3 événements en 7 jours », avec un enregistrement d'audit pour chaque décision.
Checklist rapide pour garder le pipeline sain
Un pipeline n'aide que si vous pouvez lui faire confiance semaine après semaine.
Une routine simple (quotidienne, ou quelques fois par semaine) :
- Confirmer que les événements circulent : la profondeur de la file doit bouger quand des rebonds/plaantes surviennent.
- Vérifier la DLQ : elle doit être généralement vide. Si non, inspectez quelques messages, corrigez la cause, puis rejouez en toute sécurité.
- Vérifier quelques destinataires au hasard : choisissez une poignée d'adresses envoyées récemment et vérifiez que vous pouvez voir leur historique d'événements et les horodatages.
- Vérifier que la suppression est appliquée avant l'envoi : le contrôle de suppression doit s'effectuer avant qu'un email soit mis en queue pour envoi.
- Export d'audit échantillon hebdomadaire : confirmez la présence des champs clés (recipient, event type, reason codes, message ID, campaign ID, timestamp).
Un contrôle rapide qui fonctionne bien : choisissez 3 adresses qui ont bouncé et 2 qui ont répondu. Vous devriez pouvoir tracer chacune depuis l'envoi tenté jusqu'à l'issue finale sans deviner quel système détient la vérité.
Si vous envoyez depuis une plateforme comme LeadTrain, l'objectif reste le même : garder la trace d'événements complète et la suppression automatique, pour que votre équipe consacre son temps aux bons leads plutôt qu'à combler des lacunes de données.
Exemple : une vraie semaine d'événements d'outreach
Une petite équipe SDR envoie une séquence de 600 emails à une liste ciblée. Leur pipeline est déjà en place, donc chaque rebond et plainte est capturé, stocké et traité sans surveillance manuelle.
Lundi, une adresse fait un hard bounce (utilisateur inexistant). En quelques secondes, l'événement est stocké et l'adresse est supprimée. L'étape suivante de la séquence tente d'envoyer mercredi, mais l'envoi est bloqué avant de quitter le système. Pas de rebonds répétés, pas de dommage supplémentaire.
Jeudi, un autre prospect clique sur « Signaler comme spam » après le premier email. Les plaintes sont urgentes, donc l'adresse est supprimée immédiatement, même si une relance devait partir plus tard dans la journée.
Le journal d'événements de l'équipe pourrait ressembler à :
- Lun 10:14:12 - Hard bounce - [email protected] - suppressed (raison : bounce)
- Mer 09:00:03 - Envoi bloqué - [email protected] - already suppressed
- Jeu 15:27:40 - Complaint - [email protected] - suppressed (raison : complaint)
- Ven 11:05:18 - Revue manageriale - pourquoi alex a-t-il été stoppé ? - piste complète affichée
Vendredi, un manager demande pourquoi [email protected] a cessé de recevoir des emails. Au lieu de deviner, vous montrez le payload du rebond, l'action de suppression et la tentative d'envoi bloquée ensuite. C'est la différence entre « ça a disparu » et « voici la chaîne d'événements ».
Des erreurs arrivent aussi. Si le rebond était causé par une faute de frappe dans la liste importée et que l'adresse correcte est [email protected], ne supprimez rien en silence. Conservez un enregistrement d'unsuppress approuvé (qui l'a demandé, quand et pourquoi), et ajoutez l'adresse corrigée comme nouveau destinataire.
Prochaines étapes : livrer une version minimale et itérer
Choisissez un seul objectif à livrer en premier : ingestion fiable, stockage durable ou suppression automatique. Vouloir perfectionner les trois dès le jour 1 est la manière dont les pipelines s'enlisent.
Un ordre pratique est ingestion d'abord (arrêter de perdre des données), puis stockage (pouvoir répondre aux questions), puis suppression (prendre des actions).
Une première version minimaliste mais utile :
- Capturer les événements de rebond et de plainte SES dans une file et logger chaque message.
- Stocker le payload brut plus quelques champs normalisés (timestamp, type, mailbox, message_id).
- Appliquer au départ seulement deux actions de suppression : hard bounces et plaintes.
- Ajouter une recherche simple : « Pourquoi cette adresse est-elle supprimée ? »
Gardez les règles simples pendant une semaine, puis élargissez selon ce que vous observez réellement. Si les rebonds transitoires montent pour un domaine donné, vous pourriez ajouter une règle de pause temporaire pour ce domaine plutôt que de supprimer chaque adresse.
Écrivez votre schéma d'événements et vos règles de suppression en langage clair et conservez-les à un seul endroit que l'équipe consultera vraiment.
Si vous voulez moins de parties mobiles, LeadTrain est un exemple de plateforme cold email tout-en-un qui gère domaines, boîtes, warm-up, séquences et classification des réponses dans un même flux, tout en s'appuyant sur les mêmes fondamentaux : événements précis, suppression rapide et piste d'audit claire.
FAQ
Quelle est la différence entre un rebond et une plainte, et pourquoi est-ce important ?
Un rebond signifie que l'email n'a pas pu être livré, et une plainte signifie que le destinataire a signalé votre message comme spam ou indésirable. Par défaut pratique : traitez les deux comme des signaux « arrêter d'envoyer », car les ignorer détériore rapidement la délivrabilité et gaspille des envois.
Quel est le setup AWS le plus simple pour capturer les rebonds et plaintes SES ?
Commencez par la voie fiable et simple : SES publie les événements Bounce et Complaint vers SNS, SNS diffuse vers SQS, et une Lambda lit depuis SQS. Cela évite de perdre des événements lors des pics ou des courtes pannes et rend les réessais sûrs.
Faut-il séparer production et staging pour les pipelines d'événements SES ?
Oui. Utilisez des topics SNS et des files SQS séparés par environnement pour éviter que les tests n'affectent les données de production. C'est aussi plus sûr pour le débogage : vous pouvez changer les règles en staging sans risquer la liste de suppression réelle.
Faut-il utiliser une file SQS Standard ou FIFO pour les événements SES ?
Une file Standard est le choix par défaut car elle scale et reste simple, mais elle peut livrer des messages plus d'une fois. C'est acceptable si votre Lambda est idempotente : traiter le même événement deux fois ne doit pas créer de doubles suppressions ni fausser les compteurs.
Comment gérer les événements SES incorrects ou malformés sans casser le pipeline ?
Utilisez une dead-letter queue pour que les messages malformés n'empêchent pas le trafic sain. Fixez un max receive (par exemple 5–10). Si la DLQ contient des messages, examinez la cause, corrigez le parsing/validation, puis rejouez-les après correction pour éviter d'échouer à nouveau.
Que doit faire (et ne pas faire) mon worker Lambda ?
Restez sur une tâche étroite : valider le payload, normaliser vers un schéma interne, dédupliquer avec une clé stable, stocker l'événement, puis appliquer des effets secondaires comme la suppression. Écrire l'événement avant la suppression est plus sûr : si la fonction plante, vous conservez la piste d'audit.
Comment éviter le double traitement quand SQS livre le même message deux fois ?
Supposez que des doublons arriveront et dédupliquez avec une clé stable comme message_id + recipient_email + event_type. Stockez cette clé et considérez les répétitions comme des no-ops pour éviter les double-suppressions ou l'inflation des compteurs de rebonds/plaintes.
Comment stocker les événements pour pouvoir interroger vite et auditer plus tard ?
Gardez deux couches : un enregistrement résumé rapide pour les vérifications au moment de l'envoi, et une archive brute pour les audits et le débogage. Pattern courant : résumé dans DynamoDB et JSON brut en S3, en sauvegardant la clé S3 sur l'enregistrement résumé.
Quelles sont de bonnes règles d'auto-suppression par défaut pour les rebonds et plaintes ?
Commencez par des règles défendables : supprimez immédiatement les hard bounces et les plaintes, et ne supprimez les soft bounces qu'après un seuil (par exemple 3 soft bounces en 7 jours). Enregistrez la règle qui a déclenché la suppression avec le message ID et l'horodatage pour pouvoir justifier la décision.
Comment s'assurer que la suppression est appliquée et réversible en toute sécurité ?
Traitez la liste de suppression comme la source de vérité et appliquez-la avant chaque envoi, pas seulement dans un tableau de bord. Permettez la réactivation mais de façon délibérée : exigez une raison et enregistrez qui a approuvé, tout en conservant les événements historiques.