Guía de límites de tasa API para extracciones estables de listas de prospectos
Guía de límites de tasa API para prospección: paginación, reintentos, caché y patrones de registro que mantienen las extracciones estables, repetibles y auditables.
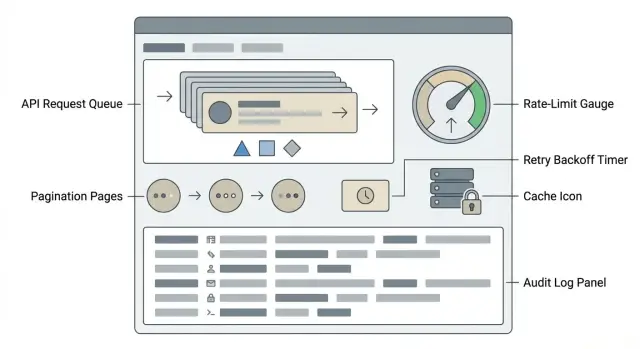
Por qué las extracciones de listas de prospectos fallan por los límites de tasa
Las extracciones de prospectos suelen fallar de formas aburridas y previsibles: una integración alcanza el límite de una API, el trabajo se ralentiza y alguien lo vuelve a ejecutar sin saber qué ya ocurrió. Parece que “la API fue inestable”, pero el problema real es que la extracción no fue diseñada para comportarse bien bajo presión.
Cuando una extracción choca con límites de tasa, aparecen varios modos de fallo que se repiten:
- Registros faltantes porque el trabajo caduca a mitad de página y nunca se reanuda limpiamente
- Duplicados porque las páginas se reintentan sin una estrategia idempotente
- Actualizaciones parciales donde algunos prospectos se enriquecen y otros quedan en blanco
- Huecos silenciosos cuando los errores se ocultan y la extracción “termina” de todas formas
- Desperdicio de créditos cuando los mismos endpoints se llaman repetidamente
Esa inestabilidad es cara. Pagas dos veces (o más) por los mismos datos, las secuencias se desordenan (el mismo lead importado o contactado dos veces) y los reportes dejan de ser fiables. A escala, pequeñas inconsistencias en listas se convierten en problemas de entregabilidad y seguimientos confusos.
El objetivo es simple: extracciones estables, repetibles y auditables.
- Estables: grandes extracciones que completan sin supervisión constante.
- Repetibles: reejecuciones que no cambian los resultados a menos que los datos fuente hayan cambiado.
- Auditables: poder responder después qué llamadas ocurrieron, qué se importó y por qué.
Las piezas prácticas son: paginación que no salte ni duplique, reintentos que recuperen sin empeorar, caché y extracciones incrementales para reducir la carga API, y registros que hagan cada ejecución explicable. Si extraes prospectos desde proveedores como Apollo hacia un sistema outbound (por ejemplo, para alimentar secuencias en LeadTrain), estas protecciones evitan que el crecimiento se vuelva caos.
Conoce los límites antes de extraer
Antes de iniciar una extracción grande, aclara qué permitirá la API. Este paso “aburrido” evita listas a medias, páginas faltantes y importaciones duplicadas más adelante.
Los rate limits van sobre velocidad. Las cuotas sobre volumen total. Los límites de concurrencia sobre cuántas solicitudes ejecutas al mismo tiempo.
- Rate limit: máximo de solicitudes por segundo o por minuto (por ejemplo: 60 solicitudes/min)
- Cuota: máximo de solicitudes por día o mes (por ejemplo: 10,000/día)
- Límite de concurrencia: máximo de solicitudes en vuelo (por ejemplo: 5 solicitudes paralelas)
La mayoría de APIs exponen señales de límite mediante cabeceras de respuesta y algunos códigos de estado comunes. Cuando integres con un proveedor, captura estas señales temprano durante una pequeña extracción de prueba.
Patrones típicos:
- HTTP 429 (Too Many Requests) y a veces 403 para enforcement de límites
Retry-Afterindicando cuánto esperarX-RateLimit-Limit,X-RateLimit-Remaining,X-RateLimit-Reset(los nombres varían)- Cabeceras específicas del proveedor como
RateLimit-*oX-Quota-*
También vigila los límites por ráfaga. Puede que te permitan 60 solicitudes/min, pero aún así te bloqueen si envías 20 en un segundo. Las ráfagas ocurren fácilmente con trabajadores paralelos, reintentos o un bucle de paginación apretado.
Para planear throughput, empieza conservador. Toma el límite publicado y apunta al 60%–80% de él. Si el límite es 60/min y cada solicitud devuelve 100 prospectos, apunta a unas 40–45 solicitudes/min (unos 4,000–4,500 prospectos/min) y mantén pocas solicitudes paralelas (a menudo 1 a 3) para evitar picos.
Paginación que no pierda ni duplique prospectos
La paginación es donde provienen la mayoría de los huecos y duplicados “aleatorios”. El objetivo es extracciones deterministas de páginas, incluso si se agregan prospectos nuevos mientras lees.
La paginación basada en offset (page=7, limit=100) es simple pero arriesgada cuando el conjunto de datos cambia. Si se añaden o editan registros en medio de la ejecución, la “página 7” puede desplazarse, causando ítems saltados o repetidos. La paginación basada en cursor (un token next_cursor) suele ser más segura porque te dice exactamente dónde continuar, aunque aún depende de que la API devuelva un orden estable.
Para mantener las páginas consistentes, solicita un orden estable y mantiene filtros fijos durante toda la ejecución. Un enfoque común es ordenar por un campo monótono como created_at, con un desempate por id para que dos registros creados a la vez no intercambien posiciones entre llamadas.
Si los datos pueden cambiar durante la extracción, “congela el universo”. Registra un timestamp de corte al inicio (por ejemplo, created_at \u003c= 2026-01-17T10:00Z) y aplícalo a cada página. Pueden llegar registros nuevos, pero no reordenarán las páginas que estás leyendo.
Reglas de parada y chequeos de sentido ayudan a saber cuándo terminar y cuándo investigar:
- Detener solo cuando la API no devuelva ítems, o no haya
next_cursor. - Rastrear IDs únicos vistos y alertar si los duplicados exceden un umbral pequeño.
- Señalar caídas súbitas en el tamaño de página.
- Mantener un total en curso y compararlo con el total reportado por la API cuando esté disponible.
- Persistir el cursor (o la última clave de orden) después de cada página para poder reanudar de forma segura.
Reintentos que recuperen sin empeorar la situación
Los reintentos ayudan cuando el problema es temporal. Empeoran la situación cuando la solicitud está mal o ya estás empujando demasiado la API. Haz los reintentos predecibles, limitados y corteses.
Separa errores que debes reintentar de errores que debes arreglar:
- Reintentar: 429 (rate limited), 408 (timeout), la mayoría de 5xx (errores servidor) y problemas de red (reset de conexión, fallos DNS).
- No reintentar: 400 (bad request), 401/403 (auth/permisos), 404 (endpoint equivocado o recurso faltante) y errores de validación.
Para 429s, respeta las instrucciones del servidor. Si recibes Retry-After, pausa ese tiempo (más un poco de aleatoriedad) y luego continúa. Ignorar Retry-After convierte una desaceleración en una caída, o peor, en una suspensión temporal.
El backoff exponencial con jitter significa esperar más tiempo tras cada fallo y añadir una pequeña demora aleatoria para que muchos trabajadores no reintenten a la vez.
- Regla de backoff: 1s, 2s, 4s, 8s, hasta un tope (por ejemplo, 30 a 60s)
- Añade jitter: aleatoriza esperas en torno al 20%–50%
- Enfriamiento: tras 429s repetidos, pausa todo el trabajo por más tiempo (por ejemplo, 2 a 5 minutos)
Pon un tope duro en reintentos. Una regla como máximo 5 intentos por solicitud, o máximo 10 minutos de reintentos totales, evita bucles infinitos.
Ejemplo: estás extrayendo 50,000 prospectos y la página 37 devuelve 429 con Retry-After: 15. Duerme 15–20 segundos, reintenta esa misma página una vez y continúa. Si recibes tres 429s seguidos, pausa brevemente en lugar de bombardear la API.
Haz las extracciones reiniciables y seguras para repetir
Una extracción estable es aquella que puedes parar, reiniciar y reejecutar sin cambiar el resultado. Eso importa cuando golpeas límites, hay un timeout o despliegas un arreglo a mitad de ejecución.
Empieza con escrituras idempotentes. En lugar de “insertar cada fila”, usa un upsert con una clave clara de desduplicación y registra lo que pasó. Claves comunes incluyen el person ID del proveedor, email normalizado, o un fallback como dominio + nombre completo.
Un conjunto de reglas de conflicto que se mantenga predecible:
- Si coincide el provider ID, trátalo como el mismo prospecto y actualiza campos.
- Si coincide el email normalizado, fusiona y conserva los campos más recientemente actualizados.
- Si no, crea un nuevo registro de prospecto y márcalo con el job ID de la extracción para trazabilidad.
- Nunca sobrescribas una bandera de unsubscribe o “no contactar” durante merges.
Haz la extracción reiniciable con checkpoints. Almacena el último cursor/token de página confirmado y un conteo de registros guardados para esa página. Solo avanza el checkpoint después de procesar y confirmar completamente la página, de modo que un fallo vuelva a reproducir como máximo una página.
Los datos del proveedor pueden cambiar: IDs se fusionan, eliminan o reciclan. Mantén una tabla de mapeo de “provider IDs vistos” a tu ID interno. Si un ID de repente apunta a otro email, ponlo en cuarentena para revisión en lugar de actualizar silenciosamente.
Ejemplo: extraes 50,000 leads cada noche en tu stack outbound (o en una plataforma como LeadTrain). Si el trabajo muere en la página 380, reinicias desde el último checkpoint, repites la página 380 de forma segura y sigues obteniendo los mismos 50,000 registros, no 50,800 con duplicados.
Caché y extracciones incrementales para reducir la carga de la API
La caché reduce llamadas API sin cambiar lo que obtienes. Ayuda mucho cuando reejecutas una extracción tras un fallo, repites las mismas búsquedas (dominios de empresa, cargos, ubicaciones) o enriqueces las mismas personas varias veces. Trata la caché como una función de seguridad, no solo como un truco de velocidad.
Un enfoque simple es cachear por una clave estable, como el provider prospect ID o el email, y almacenar solo los campos que realmente usas para outreach. Luego omite llamadas API para registros que ya tienes salvo que probablemente hayan cambiado.
Básicos de TTL: cuánto tiempo confiar en datos cacheados
El TTL (time to live) debe coincidir con la velocidad de cambio de los datos fuente y el riesgo de datos obsoletos. Datos de contacto cambian despacio, mientras que el título y la compañía pueden cambiar más rápido.
- Identificadores duros (provider ID, email, dominio de empresa): TTL largo (días a semanas)
- Detalles de perfil (cargo, seniority, ubicación): TTL medio (horas a pocos días)
- Campos de estado (unsubscribed, bounced, do-not-contact): TTL corto (minutos a horas)
Extracciones incrementales: solo nuevos o actualizados
En lugar de volver a extraer todo, guarda un checkpoint como updated_at o un token cursor del último run exitoso. La próxima vez, solicita solo registros actualizados desde ese punto. Esto reduce carga, baja la presión de rate limits y hace las reejecuciones predecibles.
La trampa común es que datos obsoletos se filtren al outreach. Protégelo validando campos críticos en el momento de envío (por ejemplo, flags de do-not-contact) y refrescando registros antes de que entren a una nueva campaña.
Si alimentas prospectos a un sistema outbound como LeadTrain, la sincronización incremental más TTLs cortos en campos relacionados con opt-out ayuda a mantener listas frescas mientras evitas llamadas innecesarias al proveedor.
Registro que haga las extracciones auditables
Cuando una extracción falla o parece “rara”, los logs son cómo pruebas qué pasó. Buenas entradas responden preguntas simples rápido: qué solicitamos, qué devolvió la API y en qué página cambió algo.
Registra un conjunto consistente de campos para cada llamada API. Manténlo estructurado (JSON es común) para poder buscar y agrupar por trabajo.
- Timestamp (inicio y fin), más latencia
- Endpoint y método, y parámetros clave de la solicitud (página/cursor, filtros, orden)
- Código de respuesta y cabeceras de rate-limit
- Conteos resultantes (registros devueltos, next cursor,
has_more) - Detalles de error (mensaje, si es retryable o no, número de intento)
Añade IDs de correlación para trazar una extracción a través de cientos o miles de llamadas. Un patrón simple es un job_id para toda la extracción y un request_id por cada llamada API. Si también guardas el último cursor exitoso con el job_id, puedes alinear logs con puntos de reanudación.
Decide cuánto de la respuesta almacenar. Las respuestas crudas facilitan auditorías, pero pueden ser caras y riesgosas. Los datos de prospectos pueden incluir información personal, así que considera la privacidad.
Un compromiso práctico es almacenar un resumen por llamada (conteos, cursores, hashes) y guardar cuerpos crudos solo cuando ocurre un error o por una ventana corta de retención. Si guardas datos crudos, redacta campos sensibles y cifra en reposo.
“Auditable” en la práctica: un responsable de sales ops pregunta por qué faltan 2,000 prospectos en la extracción del martes pasado. Con logs, puedes mostrar los parámetros de filtro exactos, la página donde empezó el rate limiting, los reintentos realizados y el cursor final guardado.
Monitorización y alertas para operaciones estables
Los límites de tasa no son solo un problema de código. Si no supervisas las extracciones mientras corren, un pequeño fallo de la API puede convertirse silenciosamente en prospectos faltantes, duplicados o una extracción que nunca termina. La monitorización debe responder rápidamente: ¿esta extracción está sana ahora?
Usa un puñado de métricas comprensibles para equipos no técnicos:
- Solicitudes por minuto (y cuán cerca estás del límite)
- Tasa de errores (4xx vs 5xx)
- Tasa de reintentos (con qué frecuencia estás retrocediendo)
- Retraso (cuánto estás detrás del tiempo de finalización esperado)
- Progreso (páginas o registros extraídos por minuto)
Las alertas deben centrarse en patrones, no en eventos aislados. Un 429 es normal. Veinte 429s seguidos indican bloqueo y desperdicio de tiempo. Lo mismo ocurre con 5xx repetidos, que a menudo indican una caída.
Disparadores útiles incluyen un pico de respuestas 429, 5xx repetidos por más de unos minutos y paginación que deja de avanzar (cursor sin cambio, o conteo de registros que no aumenta).
Los dashboards no necesitan ser sofisticados. Una vista simple con estado verde/amarillo/rojo, velocidad actual de extracción, último tipo de error y tiempo estimado restante basta para que un manager SDR decida.
Decide de antemano cuándo pausar automáticamente vs notificar a una persona:
- Auto-pausa ante 429s sostenidos o cuando el progreso está plano por una ventana establecida
- Notificar a una persona cuando la extracción está pausada o los errores persisten tras enfriamiento
- Auto-reanudar solo cuando las tasas de error bajen y el progreso vuelva de forma segura
Ejemplo: estás extrayendo 50,000 prospectos. Si los 429s suben del 1% al 40%, la auto-pausa evita que datos parciales alimenten tu sistema de outreach y reduce el riesgo de importaciones inconsistentes.
Paso a paso: ejecutar una extracción estable de prospectos
Una extracción estable es un runbook que puedes repetir. Las mismas entradas deben producir la misma salida, incluso si la API se ralentiza o falla a mitad de ejecución.
Un flujo básico:
- Plan: escribe la consulta exacta, campos a solicitar, orden y ventana temporal (por ejemplo, “creados después de 2026-01-01”). Decide tu clave única (normalmente un prospect ID).
- Dry run: extrae 1–2 páginas. Confirma la forma de la respuesta, campos requeridos y que tu clave esté siempre presente.
- Ejecución completa: comienza desde la página 1 con un cursor/offset guardado. Almacena cada página y registra el último cursor exitoso para poder reanudar.
- Verifica: compara conteos esperados (desde la API, si existe) con lo que guardaste. Revisa duplicados y campos faltantes.
- Exportar/importar: exporta un archivo final desduplicado más un pequeño manifiesto de ejecución para que alguien más pueda reejecutarlo luego.
El tamaño de lote y la concurrencia deben venir de señales, no de suposiciones. Empieza con tamaño de página de 50–100 y un worker. Si no ves respuestas por rate-limit y la latencia se mantiene, sube a 2–4 workers. Para cuando los 429s sean frecuentes o el tiempo de respuesta promedio suba, detén el aumento.
Para validación, haz una revisión de muestra rápida (20–50 registros) y luego chequeos simples: total de filas, IDs únicos de prospectos, porcentaje sin email/nombre/empresa y si alguna página fue guardada dos veces.
Documenta cada extracción en texto claro: quién la corrió, cuándo, qué cuenta API se usó, parámetros exactos, tamaño de página, concurrencia y el hash o conteo final de salida.
Ejemplo: una extracción grande realista que se mantiene consistente
Necesitas extraer 50,000 prospectos en unas 2 horas para que el equipo outbound comience mañana. Fijas un tamaño de página de 500, lo que implica unas 100 páginas. El proveedor aplica un rate limit, así que dosificas las solicitudes y planeas 429s ocasionales y errores 5xx aleatorios.
La extracción funciona así: solicita la página 1, guarda el cursor devuelto (o token de página siguiente) y escribe un checkpoint que diga "last_cursor=abc, pulled=500". Luego sigues. Si una solicitud falla, no avances. Reintenta el mismo cursor con backoff exponencial (por ejemplo, 2s, 4s, 8s), añade jitter y limita reintentos para no saturar la API.
A mitad de camino, la página 37 devuelve un 429. Tu log de auditoría para ese momento es simple y específico:
{"run_id":"2026-01-17T10:00Z","cursor":"p37","status":"retry","error":"429","backoff_seconds":8,"attempt":3}
Tras el backoff, la página 37 tiene éxito. El checkpoint se actualiza solo después de que esa página se escriba completamente en almacenamiento.
Más tarde, alguien reejecuta la misma extracción porque sospecha un bug. La reejecución lee el último checkpoint, reanuda desde la página 38 y usa escrituras idempotentes (por ejemplo, clave prospect_id + source). La lista final coincide entre ejecuciones: no faltan prospectos, no hay duplicados y hay un rastro claro que muestra exactamente dónde ocurrieron reintentos.
Errores comunes y trampas a evitar
La mayoría de fallos por límites de tasa son autoinfligidos. La solución rara vez es código ingenioso. Es evitar unas pocas trampas previsibles.
Un error es tratar todo error como reintentable. Reintentar solicitudes malas (parámetros erróneos, auth inválida, permisos faltantes) puede bombardear la API y hacerte ver abusivo. Los reintentos deben centrarse en problemas temporales como 429 y muchos 5xx, y parar rápido cuando el error es claramente permanente.
Otra trampa es demasiada concurrencia. Incluso con backoff exponencial, lanzar 50 solicitudes paralelas puede mantenerte por encima del límite para siempre. Buscas un ritmo estable, no picos. Un limitador compartido (una cola para todos los workers) suele superar a backoffs independientes en cada hilo.
La paginación también es donde se esconden problemas silenciosos de datos. La paginación por offset en un dataset cambiante puede saltar o duplicar prospectos sin error alguno. Prefiere orden estable más paginación por cursor, o usa un filtro snapshot (por ejemplo, extraer solo registros creados antes de un timestamp fijo).
Finalmente, muchas extracciones no son reiniciables. Un fallo pequeño al 80% obliga a rehacer todo, lo que incrementa la carga y aumenta la probabilidad de duplicados.
Señales de alarma a vigilar:
- Reintentar errores 400/401/403 en lugar de fallar rápido
- Paralelismo ilimitado que ignora límites globales
- Paginación por offset sin clave de orden estable
- Sin checkpoints (último cursor, último ID o último timestamp)
- Sin reglas de idempotencia al escribir resultados
Ejemplo: si extraes prospectos desde Apollo y el job se cae, un cursor guardado más una regla de “IDs vistos” te permite reanudar limpiamente. Sin eso, reejecutas todo, importas contactos duplicados y disparas más límites.
Lista rápida antes de tu próxima extracción API
Cinco comprobaciones que previenen la mayoría de fallos
Antes de ejecutar, confirma:
- Límites anotados: solicitudes por minuto, topes diarios, reglas de ráfaga y qué endpoints cuentan más.
- Paginación determinista: un método (cursor es mejor si está disponible), orden estable, ventana de filtro fija.
- Reglas de reintento seguras: backoff exponencial activado, max de reintentos fijado y regla de pausa-y-reanuda para 429s sostenidos y 5xx temporales.
- La extracción es reiniciable: se guarda un checkpoint (cursor o último timestamp/ID) y desduplicas por una clave única de prospecto.
- El registro es usable: job ID, ventana temporal, conteos de solicitudes, valores de página/cursor y un simple resumen de fin de ejecución.
Una prueba rápida de repetibilidad
Haz una pequeña extracción (por ejemplo, 200 prospectos) y reejecútala con los mismos parámetros. El conteo total debe coincidir, duplicados cero y cualquier diferencia debe ser explicable (como prospectos creados nuevos fuera de una ventana fija).
Si pasas prospectos a una herramienta outbound, verifica también el comportamiento de escritura: cuando el mismo prospecto aparece otra vez, actualiza el registro existente en lugar de crear uno nuevo.
Siguientes pasos: de extracciones estables a ejecución outbound consistente
Una extracción estable solo importa si se convierte en un workflow controlado. La pregunta final siempre es: ¿cómo pasas de una lista verificada a outreach sin cambiar los datos, dañar la entregabilidad o perder el rastro de lo ocurrido?
Congela la lista que piensas contactar. Guarda la marca de tiempo de la extracción, filtros usados y el conteo final de registros. Si necesitas enriquecer o desduplicar, hazlo una vez, registra las reglas y produce una versión lista para enviar. Esa será la fuente de verdad para la campaña.
La entregabilidad es la siguiente puerta. Incluso una lista perfecta puede fallar si la configuración de envío es débil. Usa dominios autenticados (SPF/DKIM/DMARC), evita enviar desde dominios nuevos a pleno rendimiento y calienta buzones antes de escalar.
Un traspaso práctico de “datos listos” a “outreach en marcha”:
- Asigna un dueño para la extracción y uno para la campaña (puede ser la misma persona).
- Guarda un runbook corto: dónde vive la lista, cómo se extrajo y cómo reejecutarla de forma segura.
- Importa solo el archivo congelado y listo para enviar en tu herramienta de outreach.
- Empieza con un lote pequeño y luego escala el volumen si respuestas y rebotes se ven saludables.
- Rastrea resultados de vuelta a la extracción: rebotes, bajas y tasas de respuesta por segmento.
Si quieres menos herramientas, plataformas como LeadTrain agrupan piezas comunes (dominios, buzones, calentamiento, secuencias multi-paso y clasificación de respuestas) para que el traspaso de construcción de listas a envío sea consistente. El punto principal es el mismo: repite las mismas reglas de extracción, la misma validación y los mismos pasos de lanzamiento, con un dueño claro que pueda reejecutar el proceso sin adivinar.
Preguntas Frecuentes
¿Por qué fallan tan a menudo las extracciones de prospectos cuando entran los límites de tasa?
El rate limiting suele romper las extracciones de formas que no parecen una falla clara: la tarea se queda a mitad de página, reintenta la misma página sin desduplicar o termina silenciosamente tras ocultar errores. El resultado son registros faltantes, duplicados, enriquecimientos parciales y crédito API desperdiciado.
¿Cuál es la diferencia entre rate limits, cuotas y límites de concurrencia?
Un rate limit indica la velocidad máxima de solicitudes, una cuota indica cuántas solicitudes puedes hacer en una ventana mayor y un límite de concurrencia indica cuántas solicitudes pueden estar en vuelo a la vez. Puedes estar por debajo de la cuota diaria y aun así fallar si aumentas la concurrencia y golpeas límites por minuto o por ráfaga.
¿Cómo sé si estoy alcanzando el límite de la API frente a una caída normal?
Registra códigos de estado y cualquier cabecera de límite en cada llamada, especialmente Retry-After y señales de remaining/reset. Haz una pequeña extracción de prueba para ver el comportamiento real del proveedor, porque los límites documentados y la aplicación de ráfagas a menudo difieren.
¿Cómo puedo paginar sin saltarme o duplicar prospectos?
Prefiere paginación basada en cursor cuando la API la soporte y solicita siempre un orden estable para que el orden no se reordene entre llamadas. Si el conjunto puede cambiar durante la extracción, usa un timestamp de corte fijo para que los registros nuevos no desplacen páginas y causen saltos o repeticiones.
¿Cuál es una estrategia de reintentos segura para errores 429 y timeouts?
Reintenta solo fallos claramente temporales como 429s, timeouts y la mayoría de 5xx; deja de reintentar errores permanentes como 400 o problemas de autenticación. Cuando recibas un 429, sigue Retry-After, añade un poco de aleatoriedad y limita el tiempo total de reintentos para evitar bucles infinitos.
¿Cómo puedo reejecutar una extracción fallida sin crear duplicados?
Haz tus escrituras idempotentes usando upserts con una clave estable como el prospect ID del proveedor, y conserva reglas de mezcla consistentes para que las reejecuciones no cambien el resultado. Guarda un punto de control tras cada página procesada completamente para que un fallo repita como máximo una página y no cree duplicados.
¿Cuándo debo usar caché y extracciones incrementales en lugar de volver a extraer todo?
Usa caché para consultas que repites y para datos de enriquecimiento que no necesitas refrescar en cada ejecución, y aplica un TTL acorde a la rapidez con la que cambian los campos. Para sincronizaciones continuas, las extracciones incrementales basadas en updated_at o un cursor guardado reducen la carga y hacen menos probable disparar límites.
¿Qué debo registrar para que una extracción de prospectos sea auditable?
Como mínimo, captura job ID, parámetros de la solicitud, cursor o token de página, conteos devueltos, latencia, códigos de estado y cualquier cabecera de rate-limit. Esto te permite responder qué ocurrió en la página exacta donde cambió algo y probar si los datos faltantes vinieron de la fuente, de la extracción o del paso de escritura.
¿Qué métricas y alertas realmente detectan problemas de extracción temprano?
Observa la tasa de avance, la tasa de errores separada por 4xx/5xx y con qué frecuencia estás retrocediendo, porque eso muestra si avanzas o estás atascado. Alerta sobre patrones como 429s sostenidos, 5xx repetidos por varios minutos o un cursor que deja de cambiar, ya que son señales que producen listas parciales.
¿Cómo afecta esto a mi workflow de outreach una vez que los prospectos se importan en LeadTrain?
Una cadencia constante y baja de concurrencia suele superar a las ráfagas, especialmente cuando los reintentos se acumulan. Si estás enviando prospectos a un flujo outbound como LeadTrain, las extracciones estables importan porque los duplicados pueden producir mensajes dobles y reportes confusos, y las omisiones generan secuencias y seguimientos inconsistentes.