Canal de eventos de rebotes y quejas de SES para mantener listas limpias
Construye un canal de eventos de rebotes y quejas de SES para almacenar eventos, suprimir direcciones de riesgo automáticamente y mantener un rastro de auditoría confiable.
Por qué necesitas un canal de rebotes y quejas
Un rebote ocurre cuando un correo no puede entregarse. A veces es permanente (la dirección no existe). A veces es temporal (el buzón está lleno, el servidor está ocupado o el proveedor te está limitando). Una queja ocurre cuando alguien marca tu correo como spam o lo reporta como no deseado. Ambos son señales claras para dejar de enviar a esa dirección, o al menos pausar e investigar.
Ignorar esas señales y la entregabilidad se deteriora rápido. Los proveedores aprenden que tus mensajes generan problemas, así que más correos futuros acaban en spam, incluso para buenos leads. También malgastas dinero enviando a direcciones muertas y tiempo persiguiendo gente que nunca vio tu mensaje.
Un canal de eventos de rebote y queja no va de analítica sofisticada. Es un sistema pequeño y fiable que:
- captura cada evento de rebote y queja
- suprime direcciones malas rápido
- mantiene un rastro de auditoría consultable
Esa última parte es fácil de subestimar. Una semana después alguien preguntará: “¿Realmente le enviamos a esta persona?” o “¿Por qué se suprimió esta dirección?” Si solo guardas una bandera de supresión y no historial, no puedes responder con confianza.
La configuración que sigue usa bloques comunes de AWS (SNS, SQS, Lambda) para capturar eventos, procesarlos de forma segura y almacenarlos. No cubre redacción, fuente de listas, dominios de envío ni la configuración completa de SES.
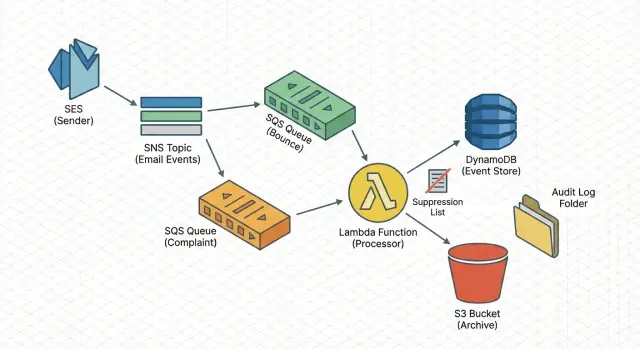
La arquitectura simple de un vistazo
Un canal fiable debe ser aburrido: cada evento aterriza en un sitio seguro, se procesa de forma repetible y deja un registro que puedes consultar después.
El flujo (ingestión -> cola -> trabajo)
Un camino probado es:
SES envía notificaciones de rebote/queja a SNS, SNS entrega a SQS, y un worker Lambda lee desde SQS.
Este enfoque absorbe picos, sobrevive a cortes breves y te permite reintentar sin bloquear el envío.
Qué hace el worker
Mantén la Lambda enfocada. Debe validar, normalizar, escribir el evento y luego aplicar efectos secundarios (como la supresión). Pasos típicos:
- validar el payload (JSON malformado, falta de email, falta de tipo)
- eliminar duplicados usando un ID de evento, o una clave estable como
message_id + recipient_email + event_type - clasificar el evento (hard bounce, soft bounce, queja)
- aplicar una acción simple (suprimir, solo advertir, ignorar)
- adjuntar contexto (dominio remitente, buzón, ID de campaña)
Almacenamiento + acciones (búsqueda rápida y auditoría)
Usa dos capas de almacenamiento: una optimizada para consultas rápidas y otra para prueba a largo plazo. Por ejemplo:
- un registro con el “último estado por dirección” para consultas rápidas
- un archivo del payload bruto para auditorías y depuración
Desde el mismo worker también puedes desencadenar acciones: añadir la dirección a una lista de supresión, alertar cuando la tasa de quejas sube, y etiquetar la campaña para rastrear qué mensaje causó el problema. Es el mismo patrón general que herramientas como LeadTrain usan para mantener la entregabilidad limpia cuando envían desde configuraciones SES separadas.
Configura SES para publicar eventos de rebote y queja
Primero, asegúrate de que SES emita las señales correctas cada vez que un correo falla o un destinatario se queja.
En SES, crea un configuration set (o reutiliza uno que ya adjuntes al correo saliente) y habilita la publicación de eventos para Bounce y Complaint. Mantén el payload lo más crudo posible. Querrás detalles después: timestamp, message ID, dirección de destino, tipo de rebote y feedback de la queja.
Trata los entornos por separado. Usa un SNS topic para producción y otro para staging para que la actividad de prueba no contamine las métricas reales.
Una configuración directa:
- Crea un topic SNS por entorno (por ejemplo, ses-events-prod y ses-events-staging).
- En tu configuration set, publica eventos Bounce y Complaint en el topic SNS correspondiente.
- Suscribe colas SQS al topic SNS. Muchos equipos usan una cola operativa para supresión/alertas y otra separada para reporting.
- Restringe la política de cada cola SQS para que solo tu topic SNS pueda enviar mensajes (restringe por SourceArn y cuenta).
- Envía un pequeño lote de prueba y confirma que recibes tanto mensajes de rebote como de queja con los campos que esperas.
Bufferiza eventos de forma segura con SQS
SQS es el amortiguador de seguridad entre los eventos SES y tu código. Desacopla el sistema para que un pico de rebotes o quejas no sobrecargue tu worker. Si Lambda está caída unos minutos, los eventos esperan en la cola en lugar de desaparecer.
Para la mayoría de pipelines, una cola Standard es la opción más simple. Puede entregar mensajes más de una vez, por lo que el worker debe ser idempotente (seguro de ejecutar dos veces). Elige FIFO solo si realmente necesitas orden estricta o deduplicación a nivel de cola.
Standard vs FIFO en palabras sencillas
FIFO puede tener sentido si necesitas:
- orden estricto para la misma dirección de correo
- deduplicación a nivel de cola
- volumen predecible y menor que no choque con los límites de FIFO
Dead-letter queue y límites de reintento
Usa una dead-letter queue (DLQ) para que mensajes tóxicos no bloqueen tráfico sano. Un punto de partida seguro:
- max receives: 5 a 10
- retención de mensaje: lo bastante larga para investigar (unos días es común)
- alarmas cuando la profundidad de la DLQ sea mayor a 0
Mantén los mensajes pequeños, pero no descartes el contexto. Almacena el payload completo del evento SES (o el body completo del mensaje SNS) para poder auditar después. Si cambias reglas de supresión en el futuro, el payload original es lo que te permite explicar por qué se suprimió una dirección.
Procesa eventos con un worker Lambda pequeño
El worker Lambda traduce eventos SES en las decisiones que te importan. Mantén la tarea estrecha: parsea un mensaje, extrae unos pocos campos, escribe un registro de evento y actualiza el estado de supresión cuando sea necesario.
Empieza normalizando los payloads de SES en un esquema interno único. Los distintos tipos de evento no siempre se parecen, así que elige una forma consistente y mapea todo a ella. Un mínimo práctico:
- event_type (bounce, complaint, delivery)
- message_id (SES mail.messageId)
- recipient_email
- event_time (un timestamp consistente)
- source (configuration set, identidad de envío o nombre del sistema)
Normaliza los tipos de rebote temprano. Mantén “bounce” como el tipo principal y almacena hard vs soft como un campo separado. Haz lo mismo para las quejas: guarda subtipos si existen, pero no permitas que fragmenten tu flujo central.
La idempotencia importa porque SQS puede entregar mensajes más de una vez. Usa una clave estable como message_id + recipient_email + event_type. Antes de escribir, comprueba si ya almacenaste esa clave. Si es así, reconoce y sal. Eso evita doble supresión y mantiene los conteos honestos.
Sé estricto con los timestamps. Guarda el timestamp del evento en un formato consistente (por ejemplo, cadenas ISO). También guarda received_at por separado para detectar retrasos.
Una buena regla: escribe primero el registro del evento y luego aplica los efectos secundarios. Si el worker falla después de escribir pero antes de suprimir, puedes volver a ejecutar la supresión sin perder la pista de auditoría.
Almacena eventos para velocidad y rastro de auditoría
Quieres dos cosas a la vez: respuestas rápidas (“¿es seguro enviar a esta dirección?”) y un historial completo cuando algo va mal.
Almacena un pequeño resumen que puedas consultar rápido y guarda el payload AWS bruto por separado. El payload bruto es tu fuente de verdad cuando necesitas explicar un pico de quejas o probar por qué se suprimió una dirección.
Un registro resumen puede ser pequeño:
- event_id (tu ID único)
- message_id (de SES)
- recipient (dirección de correo)
- type y subtype (bounce, complaint; hard/soft)
- reason (texto corto o código)
Un emparejamiento común es DynamoDB para búsquedas rápidas y S3 para archivo. DynamoDB funciona bien cuando tu ruta de envío necesita una comprobación rápida de “¿este destinatario rebotó antes?”. S3 es barato para guardar JSON bruto a escala.
Un patrón simple: escribe el resumen en DynamoDB, guarda el payload bruto en S3 usando una clave que incluya la fecha y message_id, y almacena esa clave S3 en el registro de DynamoDB.
La retención es una decisión de política. Algunos equipos mantienen los resúmenes a largo plazo y expiran los payloads brutos antes. Si necesitas auditorías profundas, haz lo contrario.
Auto-supresión de direcciones malas (mantén reglas simples)
La auto-supresión es donde la canalización paga por sí misma. La meta no es un modelo perfecto. Es parar direcciones claramente malas rápido y poder explicar la decisión después.
Empieza con reglas fáciles de defender:
- Hard bounce: suprimir inmediatamente.
- Queja: suprimir inmediatamente.
- Soft bounce: suprimir solo después de N eventos en una ventana móvil (por ejemplo, 3 soft bounces en 7 días).
- Baja (si la capturas por separado): suprimir inmediatamente.
Los soft bounces son difíciles porque pueden ser temporales. La regla de umbral evita reaccionar en exceso a un mal día, mientras elimina direcciones que fallan repetidamente.
Mantén una pequeña allowlist para dominios internos, buzones de prueba y direcciones seed. Revísala y manténla ajustada para que no oculte problemas reales.
Cada supresión debe ser auditable. Guarda:
- la regla que disparó la supresión
- los metadatos del evento que la disparó (timestamp, message ID, tipo de rebote)
- el contexto de origen (ID de campaña, dominio remitente, buzón)
Ese rastro hace la automatización más segura y facilita revertir cuando alguien dice “Este lead es válido, por favor quítenlo de la supresión.”
Mantén una lista de supresión en la que puedas confiar
Una lista de supresión solo ayuda si todo el mundo la trata como la fuente de verdad. Eso significa dos cosas: un estado claro por destinatario y un único lugar que el sistema de envío consulte antes de cada envío.
Muchos equipos funcionan bien con tres estados:
- activo: ok para enviar
- suprimido: no enviar
- pendiente-revisión: en pausa hasta que un humano confirme
La ruta de envío no debería adivinar. Antes de enviar un correo, haz una búsqueda y bloquea el envío si el estado es suprimido o pendiente-revisión. Pon esa comprobación en el servicio que arma la lista de envío, no en un dashboard que alguien pueda olvidar usar.
Deshacer supresiones es donde ocurren errores. Hazlo posible, pero deliberado. Requiere una razón y registra quién lo aprobó. Si tienes múltiples herramientas, simplifica: solo un sistema puede cambiar el estado de supresión y todo lo demás debe llamarlo.
Además, no sobrescribas la historia. Cada cambio de estado debe crear un evento de auditoría: qué cambió, de qué estado a qué estado, cuándo y qué lo desencadenó.
Ejemplo: una dirección hace hard bounce el lunes y se suprime automáticamente. El jueves, el lead responde desde una dirección corregida. Mantienes la dirección antigua suprimida, marcas la nueva como activa y registras ambos cambios con notas. En plataformas como LeadTrain, ese tipo de historial ayuda a clasificar respuestas y a que la lógica de envío dependa de una decisión de supresión consistente.
Errores comunes y cómo evitarlos
Una canalización puede parecer terminada el primer día y aun así tomar malas decisiones después. La mayoría de problemas vienen de pequeñas suposiciones que sesgan métricas o disparan supresión equivocada.
Una trampa es tratar “delivered” como “en bandeja de entrada”. SES puede decir que el servidor receptor aceptó el mensaje, no dónde aterrizó. Usa delivery como señal de salud de envío, no como prueba de colocación en bandeja.
Otro problema es tratar todos los rebotes igual. Un rebote transitorio no debe recibir la misma respuesta que uno permanente. La sobre-supresión reduce tu lista y puede ocultar problemas reales como pacing, contenido o reputación de un dominio nuevo.
Errores comunes y soluciones:
- Sin reintentos: si tu worker falla una vez, el evento desaparece. Solución: SQS + reintentos + DLQ + procesamiento idempotente.
- Sin clave de dedupe: el mismo evento se procesa dos veces. Solución: almacena un ID de evento único e ignora repeticiones.
- Suprimir por cada rebote: problemas temporales se vuelven penalizaciones permanentes. Solución: suprime inmediatamente hard bounces y quejas; usa umbrales para soft bounces.
- Guardar solo agregados: no puedes responder “¿por qué se suprimió esto?”. Solución: guarda eventos brutos con message IDs, timestamps y la regla que se disparó.
- Asumir que delivery es inbox: las métricas parecen bien mientras las respuestas caen. Solución: separa delivered de engaged y mira tasas de respuesta por buzón y dominio.
Ejemplo: envías 2,000 correos y ves 1,980 delivered. Si 30 son soft bounces de un solo dominio y los suprimes inmediatamente, puedes eliminar leads válidos. Una regla mejor es “suprimir solo hard bounces y quejas, y suprimir soft bounces solo después de 3 eventos en 7 días”, con un registro de auditoría para cada decisión.
Lista de comprobación rápida para mantener la canalización sana
Una canalización solo ayuda si puedes confiar en ella semana tras semana.
Una rutina simple (diaria o varias veces por semana):
- Confirma que los eventos fluyen: la profundidad de la cola debería variar cuando ocurren rebotes/quejas.
- Revisa la DLQ: normalmente debería estar vacía. Si no, inspecciona algunos mensajes, arregla la causa y reprocésalos de forma segura.
- Comprueba algunos destinatarios al azar: elige unas direcciones enviadas recientemente y verifica que puedes ver su historial de eventos y timestamps.
- Verifica que la supresión se aplique antes de enviar: las comprobaciones de supresión deben ocurrir antes de que un correo se encole para enviar.
- Exporta una muestra de auditoría semanalmente: confirma que los campos clave están presentes (recipient, event type, reason codes, message ID, campaign ID, timestamp).
Un chequeo rápido que funciona bien: elige 3 direcciones que rebotaron y 2 que respondieron. Deberías poder trazar cada una desde el envío intentado hasta el resultado final sin adivinar qué sistema tiene la verdad.
Si gestionas envíos desde una plataforma como LeadTrain, la meta es la misma: mantener el rastro de eventos completo y la supresión automática para que tu equipo dedique tiempo a buenos leads en lugar de parchear huecos de datos.
Ejemplo: una semana real de eventos de outreach
Un pequeño equipo SDR ejecuta una secuencia de 600 correos a una lista segmentada. Su pipeline ya está conectado, así que cada rebote y queja se captura, almacena y actúa sin que nadie lo vigile.
El lunes, una dirección hace hard bounce (usuario inexistente). En segundos, el evento se almacena y la dirección se suprime. El siguiente paso de la secuencia intenta enviar el miércoles, pero el envío se bloquea antes de salir del sistema. No hay rebotes repetidos ni daño extra.
El jueves, otro prospecto marca “Report spam” tras el primer correo. Las quejas son urgentes, así que la dirección se suprime inmediatamente, incluso si un seguimiento hubiera salido más tarde ese día.
El registro de eventos del equipo podría verse así:
- Lun 10:14:12 - Hard bounce - [email protected] - suprimido (razón: bounce)
- Mié 09:00:03 - Envío bloqueado - [email protected] - ya suprimido
- Jue 15:27:40 - Queja - [email protected] - suprimido (razón: complaint)
- Vie 11:05:18 - Revisión gerencial - ¿por qué se detuvo alex? - rastro completo mostrado
El viernes, un manager pregunta por qué [email protected] dejó de recibir correos. En lugar de adivinar, muestras el payload del rebote, la acción de supresión y el intento de envío bloqueado posterior. Esa es la diferencia entre “desapareció” y “aquí está la cadena de eventos”.
También ocurren errores. Si el rebote fue causado por un error tipográfico en la lista subida y la dirección correcta es [email protected], no borres entradas a la ligera. Mantén un registro de des-supresión aprobado (quién lo pidió, cuándo y por qué) y añade la dirección corregida como nuevo destinatario.
Próximos pasos: lanza una versión pequeña e itera
Elige un resultado para lanzar primero: ingestión fiable, almacenamiento duradero o supresión automática. Intentar perfeccionar los tres el primer día es la forma en que los pipelines se estancan.
Un orden práctico es: ingestión primero (deja de perder datos), luego almacenamiento (responde preguntas después) y finalmente supresión (toma acción).
Un primer lanzamiento pequeño que ya aporta valor:
- Captura eventos de rebote y queja de SES en una cola y registra cada mensaje.
- Almacena el payload bruto más algunos campos normalizados (timestamp, type, mailbox, message_id).
- Aplica solo dos acciones de supresión al principio: hard bounces y quejas.
- Añade una búsqueda simple: “¿Por qué se suprimió esta dirección?”
Mantén las reglas pequeñas durante una semana y amplíalas según lo que realmente veas. Si los rebotes transitorios aumentan en un dominio, podrías añadir una pausa temporal para ese dominio en lugar de suprimir cada dirección.
Documenta tu esquema de eventos y reglas de supresión en lenguaje claro y mantenlo en un lugar que el equipo realmente lea.
Si quieres menos piezas móviles, LeadTrain es un ejemplo de plataforma de cold email todo-en-uno que agrupa dominios, buzones, warm-up, secuencias y clasificación de respuestas en un flujo, mientras sigue los mismos fundamentos: eventos precisos, supresión rápida y un rastro de auditoría claro.
Preguntas Frecuentes
¿Cuál es la diferencia entre un rebote y una queja, y por qué debería importarme?
Un rebote significa que el correo no pudo entregarse, y una queja significa que el destinatario marcó tu mensaje como spam o no deseado. La regla práctica por defecto es tratar ambos como señales de “dejar de enviar”, porque ignorarlas degrada la entregabilidad rápidamente y supone desperdicio de envíos.
¿Cuál es la configuración AWS más simple para capturar rebotes y quejas de SES?
Empieza con la ruta fiable y sencilla: SES publica eventos Bounce y Complaint en SNS, SNS hace fan-out a SQS, y una Lambda lee desde SQS. Esto evita perder eventos durante picos o interrupciones breves y hace que los reintentos sean seguros.
¿Debería separar producción y staging para las canalizaciones de eventos SES?
Usa topics SNS y colas separadas por entorno para que los rebotes y quejas de pruebas no contaminen los datos de producción. También facilita depurar porque puedes cambiar reglas en staging sin arriesgar tu lista de supresión real.
¿Debería usar una cola SQS Standard o FIFO para eventos SES?
Una cola Standard suele ser la opción por defecto porque escala y es simple, pero puede entregar mensajes más de una vez. Eso está bien siempre que tu Lambda sea idempotente, es decir, que procesar el mismo evento dos veces no cree dobles conteos ni doble supresión.
¿Cómo manejo eventos SES dañados o malformados sin romper la canalización?
Usa una dead-letter queue para que los mensajes corruptos no bloqueen el tráfico sano, y fija un max receive como 5–10. Si llega algo a la DLQ, investiga la causa y reprocésalo solo después de arreglar la validación o el parseo, de otro modo fallará de nuevo.
¿Qué debe (y qué no debe) hacer mi worker Lambda?
Mantenla estrecha: valida el payload, normaliza campos en un esquema interno, dedupe con una clave estable, almacena el evento y luego aplica efectos colaterales como la supresión. Es más seguro escribir el evento antes de suprimir porque así conservas la pista de auditoría aunque la función falle a mitad de camino.
¿Cómo evito el reprocesamiento doble cuando SQS entrega el mismo mensaje dos veces?
Asume que habrá duplicados y dedupe con una clave estable como message_id + recipient_email + event_type. Almacena esa clave y trata las repeticiones como no-ops para no suprimir dos veces ni inflar conteos de rebotes y quejas.
¿Cómo debo almacenar eventos para poder consultar rápido y auditar después?
Mantén dos capas: un registro rápido con el “último estado por dirección” para las comprobaciones en el momento de envío, y un archivo con el payload raw para auditorías y depuración. Un patrón común: resumen en DynamoDB y JSON bruto en S3, guardando la clave S3 en el registro de DynamoDB.
¿Cuáles son reglas por defecto razonables para la auto-supresión ante rebotes y quejas?
Empieza con reglas fáciles de defender: suprime hard bounces y quejas inmediatamente, y suprime soft bounces solo tras un umbral (por ejemplo, 3 en 7 días). Registra la regla que disparó la supresión junto con message ID y timestamp para poder explicar decisiones más tarde.
¿Cómo me aseguro de que la supresión se aplique realmente y se pueda revertir con seguridad?
Trata la lista de supresión como la fuente de la verdad y aplícala antes de cada envío, no solo en un dashboard que alguien pueda olvidar. Permite deshacer la supresión pero de forma deliberada: exige una razón y registra quién aprobó el cambio, manteniendo intacto el historial de eventos.