De sandbox a producción en AWS SES para correo saliente: un plan
Pasos para pasar de sandbox a producción en AWS SES para correo saliente, más un plan práctico sobre límites, ramp y monitorización para que no te bloqueen al escalar.
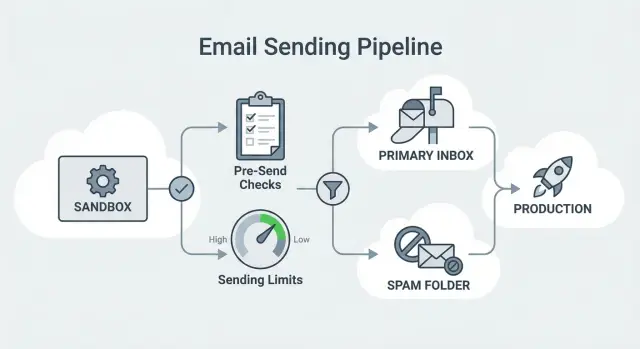
Por qué el sandbox de SES bloquea las escaladas de envío
Cuando creas (o habilitas) Amazon Simple Email Service (SES), tu cuenta normalmente empieza en el sandbox de SES. Es un modo de seguridad: AWS te deja probar envíos, pero aplica protecciones estrictas hasta que demuestres que puedes enviar de forma responsable.
Esas protecciones son un verdadero problema para el outreach en frío. En el sandbox estás limitado por bajo volumen diario, baja velocidad por segundo y (lo más importante) solo destinatarios verificados. Esa última regla bloquea el outbound por completo: no puedes escribir a prospectos reales a menos que verifiques cada dirección o dominio primero.
Por eso los equipos suelen encontrarse con fricción durante la transición “AWS SES sandbox a producción”. Puedes tener tu secuencia lista, la lista importada y un plan de ramp, y aun así descubrir que tu primer lote no se envía — o que se envía tan despacio que los follow-ups se desincronizan y la campaña pierde impulso.
Un patrón común de fallo se ve así:
- Las pruebas a unas pocas direcciones internas funcionan, así que todo parece listo.
- Lanzan a prospectos y los envíos fallan porque los destinatarios no están verificados.
- Tras la aprobación, la tasa de envío sigue siendo tan baja que los pasos se alargan y los resultados bajan.
- Al aumentar el volumen, los errores de throttling obligan a pausas mientras pides límites mayores.
Esto golpea con fuerza a equipos de SDR y fundadores porque necesitan un rendimiento diario constante. Si tu plan depende de envíos consistentes (por ejemplo, 200 prospectos nuevos al día en secuencias multietapa), el sandbox convierte el outreach en un trabajo de arranque y parada.
Un aviso más: el sandbox no es una prueba realista de entregabilidad. La entregabilidad real depende de autenticación, warm-up, calidad de lista, control de rebotes/quejas y un ramp gradual. El sandbox existe principalmente para frenarte hasta que AWS confíe en que no vas a generar abuso o malas experiencias para destinatarios.
Sandbox vs producción: qué cambia realmente
Sandbox y producción difieren en lo que más importa para el outbound.
En el sandbox solo puedes enviar a identidades verificadas (direcciones de email específicas o dominios enteros que hayas verificado). En producción puedes escribir a destinatarios reales sin verificar cada uno.
Tus límites también cambian. Las cuotas del sandbox son pequeñas. Las de producción son mayores, pero siguen aplicándose. Aun puedes chocar con límites diarios y throttling por segundo, y AWS ajusta cuotas según tu historial de envío.
El otro gran cambio es la reputación. En sandbox no construyes historial significativo. En producción, las tasas de rebote y queja empiezan a moldear tu capacidad para escalar a largo plazo.
En la práctica, los equipos outbound sienten tres diferencias inmediatas:
- A quién puedes escribir: solo verificados vs envío abierto
- Qué tan rápido puedes enviar: topes bajos vs cuotas más altas (pero aún limitadas)
- Cuánto importan los errores: las métricas de producción afectan rápido la reputación y el throughput
Qué evalúa realmente AWS
Cuando solicitas acceso a producción (y después de que te aprueben), AWS busca señales de que no vas a perjudicar a destinatarios o redes. Dos métricas importan más:
- Tasa de rebote: rebotes altos suelen indicar mala higiene de listas.
- Tasa de quejas: las quejas sugieren correo no deseado, segmentación poco clara o contenido engañoso.
AWS también valora tu caso de uso y cómo gestionas las bajas. Para outbound eso suele significar: ¿estás mandando a personas que razonablemente podrían esperar tu mensaje, y pueden dejar de recibirlo con facilidad?
El acceso a producción no es la meta final. Es permiso para operar a escala real. Si escalas demasiado rápido, ignoras las bajas o envías a listas débiles, aún puedes sufrir throttling o que te obliguen a reducir ritmo.
Preparación previa antes de solicitar
Antes de pedir que AWS te mueva del sandbox a producción, prepara tu base de envío. Las aprobaciones en SES (y la estabilidad a largo plazo) son mucho más sencillas cuando tu identidad y procesos parecen intencionales.
Empieza con un dominio de envío dedicado y separado del dominio corporativo principal. Muchos equipos usan un dominio estrechamente relacionado para que los experimentos outbound no pongan en riesgo la reputación del buzón principal.
Después, configura la autenticación: SPF, DKIM y DMARC. No necesitas una política DMARC agresiva el primer día, pero sí alineamiento. Un objetivo simple es:
- El DKIM de SES firma y coincide con el dominio en tu dirección From
- SPF está publicado
- DMARC está publicado para que los proveedores puedan verificar legitimidad
También define identidad y manejo de respuestas desde el inicio:
- Usa un nombre From que parezca una persona real o un equipo.
- Usa una dirección que pueda recibir respuestas.
- Mantén los detalles From estables (no cambies nombres y direcciones cada semana).
Finalmente, comprométete con una regla clara de bajas. Incluso en outbound en frío, “stop” debe significar detenerse — inmediata y consistentemente en todas las listas y secuencias.
Si quieres una operación más sencilla, LeadTrain (leadtrain.app) está diseñado para mantener dominios, buzones, warm-up, secuencias y clasificación de respuestas en un solo lugar, de modo que menos detalles se pierdan durante la puesta en marcha.
Paso a paso: solicitar acceso a producción en SES
Pasar a producción es una solicitud de soporte. Tus respuestas importan tanto como la configuración técnica.
1) Encuentra la solicitud en la consola de AWS
Abre Amazon SES en la región de AWS desde la que vas a enviar. En el área de estado de cuenta (donde indica que estás en el sandbox), elige la opción para solicitar acceso a producción o un aumento de límites de envío. Eso abre un formulario de caso de soporte.
2) Describe tu caso de uso en lenguaje claro
Sé específico y fácil de entender. Explica a quién envías, por qué les envías, cómo obtuviste las direcciones y cómo pueden optar por no recibir más mensajes.
Las solicitudes más sólidas suelen cubrir:
- Audiencia: a quién envías (por ejemplo, prospectos B2B que encajan en tu ICP)
- Origen: cómo se obtienen las direcciones (investigación manual, proveedor verificado, tus propios formularios)
- Baja: cómo dejan de recibir mensajes (enlace o “responder STOP”), y la rapidez con la que lo aplicas
- Ramp: cómo empezarás pequeño y aumentarás gradualmente
- Higiene: qué haces con rebotes y quejas
3) Proporciona lo que AWS suele pedir
Espera preguntas como ejemplos de asuntos y contenido, la identidad de tu empresa, tu sitio web y cómo evitas mensajes engañosos. A menudo preguntan exactamente cómo gestionas rebotes duros, quejas y solicitudes de baja.
4) Si te rechazan o hacen preguntas de seguimiento
No reenvíes el mismo texto. Atiende la preocupación específica (normalmente calidad de lista, claridad del opt-out o caso de uso poco claro). Si hace falta, pide primero un límite menor y súbelo más tarde cuando tengas métricas estables.
Planea tus límites de envío para no encontrarte con un techo
Pasar del sandbox a producción es solo la mitad del trabajo. La otra mitad es asegurarte de que tu plan de outreach encaje con las cuotas de SES.
El volumen outbound no es “leads x 1 email”. Son prospectos nuevos más follow-ups a lo largo de una secuencia, multiplicados por los emisores activos.
Una forma simple de estimar volumen diario:
- Cuenta buzones de envío activos.
- Multiplica por prospectos nuevos por buzón por día.
- Multiplica por el número medio de emails que un prospecto recibe (inicial más seguimientos).
- Añade un buffer (20–30%) para días irregulares y reintentos.
Ejemplo: 6 SDRs empiezan con 40 prospectos nuevos cada uno por día. Cada prospecto recibe alrededor de 3 emails en total con el tiempo. Eso es 6 x 40 x 3 = 720 emails/día. Con buffer, planea alrededor de 900.
También ten en cuenta la calidad de las listas. Los rebotes siguen contando como envíos. Si una fuente genera más rebotes, consumirás cuota más rápido y dañarás la reputación al mismo tiempo.
Para el ramp, empieza más despacio que tu objetivo incluso si SES te da margen. Un ramp conservador semanal suele ser suficiente para proteger la reputación:
- Días 1-2: 10–20% del volumen objetivo
- Días 3-4: 30–50%
- Días 5-7: 60–80%
- Semana 2: acercarse al 100% si las métricas se mantienen estables
Solicita límites mayores pronto si esperas alcanzar tu cuota en las próximas 2–4 semanas (por ejemplo, vas a añadir más personas o tu secuencia está por llegar a estado estable de volumen de follow-ups).
Monitorización para mantenerte en acceso de producción
Una vez en producción, mantenerte allí depende en gran parte de mantener señales limpias y predecibles.
Un tablero semanal simple
Revisa un conjunto pequeño de métricas semanalmente (y diariamente durante el ramp):
- Tasa de entrega
- Tasa de hard bounces
- Tasa de soft bounces
- Tasa de quejas
- Tasa de bajas
Si la entrega cae mientras los rebotes suben, sospecha de calidad de lista o problemas de autenticación. Si las quejas suben, revisa targeting, frecuencia o copy.
Señales de alerta temprana y qué hacer
El throttling suele aparecer tras cambios repetibles en métricas, no por un mal día aislado. Vigila patrones como aumento de rebotes después de subir una nueva lista, o picos de quejas tras cambiar el copy.
Mantén reglas simples para no debatir en el momento:
- Si suben las quejas, pausa el segmento más nuevo y revisa targeting y mensajes.
- Si suben los hard bounces, detén esa fuente de listas y limpia los datos antes de reanudar.
- Si los soft bounces se mantienen altos varios días, frena el ramp hasta que se estabilice.
Un registro corto de cambios ayuda mucho. Anota cambios mayores (nuevo dominio, nueva fuente de lista, nuevo set de asuntos, aumento de volumen). Cuando las métricas se muevan, sabrás qué lo causó probablemente.
Manejo de rebotes, quejas y bajas para outbound
Al pasar de sandbox a producción, la forma más rápida de perder impulso es ignorar rebotes, quejas y bajas. SES vigila estas tasas de cerca, y los proveedores de buzón también.
Rebotes: duro vs blando
Los hard bounces son fallos permanentes (el buzón no existe, dominio inválido). Suprimelos de inmediato y no reintentes.
Los soft bounces suelen ser temporales (buzón lleno, error temporal, limitación). Reintenta con cautela. Si la misma dirección hace soft bounce repetidamente, suprimela.
Una regla segura:
- Hard bounce: suprimir permanentemente.
- Soft bounce repetido: suprimir tras algunos intentos fallidos.
- Pico súbito de rebotes: pausar y diagnosticar antes de continuar.
Quejas y bajas
Las quejas (“Report spam”) son una señal negativa fuerte. La mejor prevención es segmentación estricta y expectativas claras, no trucos de redacción.
Las bajas son normales en outbound. Trátalas como obligatorias. Si alguien se da de baja, suprímelo inmediatamente en todas las secuencias y listas.
Errores comunes que desencadenan throttling o bloqueos
Muchos equipos se aprueban y luego tienen problemas porque su primera semana no coincide con lo que describieron a AWS.
Los patrones que más suelen causar throttling:
- Subir volumen demasiado rápido justo después de la aprobación
- Usar fuentes de lista débiles (antiguas, scraped, no verificadas)
- Cambiar demasiadas variables durante el ramp (dominio, oferta, audiencia y volumen a la vez)
- Dejar que se acumulen señales negativas (bajas lentas, rebotes repetidos)
- Mezclar outbound frío con correo transaccional importante en el mismo dominio o identidad
Para estar seguros, cambia una cosa a la vez, haz ramp predecible y mantén el outbound separado del correo transaccional.
Ejemplo: mover un equipo pequeño de outbound a producción en SES
Considera un equipo de 3 SDRs con una secuencia de 14 días. Cada SDR añade 25 prospectos nuevos por día. Si la secuencia promedia unas 4 emails por prospecto, las cuentas en estado estable serían:
- Prospectos nuevos por día: 3 x 25 = 75
- Emails promedio por prospecto: 4
- Envíos diarios esperados en estado estable: 75 x 4 = 300 emails/día
No empezará a 300 el primer día. Los follow-ups se acumulan con el tiempo, así que el volumen sube a medida que la secuencia “se carga”. Por eso tu plan de producción debe incluir un ramp, no solo un interruptor.
Un ramp realista podría ser:
- Días 1-2: límite en 60–80/día total
- Días 3-4: límite en 120–160/día
- Días 5-7: límite en 200–250/día
- Semana 2: acercarse al estado estable (alrededor de 300/día)
Si las quejas suben a mitad de ramp (por ejemplo, 2 quejas de 150 envíos), no sigas forzando. Congela el crecimiento 48 horas, recorta volumen 30–50%, ajusta targeting y copy, y confirma que el manejo de bajas funciona.
Lista rápida y siguientes pasos
La mayoría de los problemas al pasar de “AWS SES sandbox a producción” vienen de fundamentos faltantes que aparecen después como rebotes, quejas o throttling.
Chequeo rápido de 5 minutos:
- El acceso a producción está aprobado y la identidad del dominio From está verificada.
- SPF, DKIM y DMARC están publicados y alineados con el dominio From.
- Existe un plan de ramp (límites diarios y aumentos graduales) que encaja con tus límites de SES.
- La monitorización está en marcha, con un responsable nombrado.
- Rebotes, quejas y bajas se suprimen de inmediato.
Si quieres respuestas más rápidas cuando AWS pida aclaraciones (o cuando las métricas caigan), documenta internamente tres cosas: la fuente de listas, tu plan de ramp y la regla exacta de opt-out.
Un siguiente paso práctico es un ensayo de producción de una semana: un dominio, una pequeña cartera de buzones, un segmento estrecho de leads recientes y límites conservadores. Si las señales se mantienen limpias, acelera. Si no, pausa, arregla la causa y reanuda más despacio.
Preguntas Frecuentes
¿Por qué Amazon SES comienza en sandbox y por qué es un problema para outbound?
El sandbox de SES es un modo de seguridad. Limita el volumen diario y la velocidad de envío, y exige que envíes solo a destinatarios verificados, lo que impide el outreach en frío hasta que tengas acceso a producción.
¿Qué significa realmente “solo destinatarios verificados” en el sandbox de SES?
En el sandbox, SES solo entrega a identidades que has verificado, como una dirección de correo específica o todo un dominio que controlas. Los prospectos no están verificados, así que tus envíos fallan incluso si las plantillas y secuencias funcionan en pruebas internas.
¿Qué cambia cuando SES pasa de sandbox a producción?
Podrás enviar a cualquier destinatario sin verificar cada dirección, y tus cuotas serán mayores que en sandbox. Aun así, hay topes diarios y limitaciones por segundo, y las tasas de rebote y de quejas empezarán a afectar tu capacidad de escalar.
¿Qué debo configurar antes de solicitar acceso a producción en SES?
Configura un dominio de envío dedicado y publica SPF, DKIM y DMARC para que el dominio From esté alineado con la autenticación. Asegúrate de que la dirección From pueda recibir respuestas, que la identidad permanezca estable y que el proceso de baja sea claro y se aplique de inmediato.
¿Qué debo escribir en la solicitud de acceso a producción de AWS SES para outbound en frío?
Explica a quién envías, por qué pueden esperar tu mensaje, cómo obtuviste las direcciones y cómo funcionan las bajas. Añade un plan de ramp realista y describe cómo gestionas rebotes, quejas y bajas, porque AWS evalúa si vas a enviar de forma responsable.
¿Qué métricas le importan más a AWS después de que me aprueben?
Suelen fijarse en la tasa de rebote y en la tasa de quejas como señales clave de la calidad de listas y de la experiencia del destinatario. También quieren ver manejo sencillo de bajas y mensajes no engañosos para que los destinatarios puedan dejar de recibir correos fácilmente.
¿Cómo calculo los límites de envío que realmente necesitaré?
Calcula los envíos totales, no solo los leads nuevos, porque los seguimientos se acumulan en secuencias multietapa. Multiplica buzones activos por prospectos nuevos por buzón y por el número medio de emails que recibe cada prospecto en la secuencia, y añade un buffer para no topar con la cuota a mitad de semana.
¿Con qué rapidez debería aumentar el volumen después de pasar a producción?
Comienza por debajo del volumen objetivo aunque SES te dé margen, e incrementa gradualmente siempre que rebotes y quejas se mantengan estables. Si subes demasiado rápido, puedes activar throttling, provocar desfases en los seguimientos y dañar las señales tempranas de reputación.
¿Cuál es la forma más segura de manejar rebotes, quejas y bajas en SES?
Suprime inmediatamente los hard bounces y no reintentes, pues las fallas repetidas desperdician cuota y dañan métricas. Aplica las bajas al instante en todas las secuencias y listas, y trata las quejas como una señal para detenerse e investigar el targeting, el copy y la frecuencia.
¿Cómo evito throttling o bloqueos después de obtener acceso a producción?
Cambia una cosa a la vez y lleva un registro sencillo de cambios (fuente de lista, copia, dominio o volumen). Si las operaciones están dispersas entre herramientas, un sistema unificado como LeadTrain puede ayudar a mantener dominios, warm-up, secuencias y clasificación de respuestas consistentes para que se pierdan menos detalles al escalar.