SES Bounce- und Complaint-Event-Pipeline für saubere Listen
Baue eine SES-Bounce- und Complaint-Pipeline, um Events zu speichern, riskante E‑Mails automatisch zu suppressen und eine Audit‑Spur zu behalten, der dein Team vertraut.
Warum du eine Bounce- und Complaint-Pipeline brauchst
Ein Bounce tritt auf, wenn eine E-Mail nicht zugestellt werden kann. Manchmal ist das dauerhaft (die Adresse existiert nicht). Manchmal ist es temporär (Mailbox voll, Server beschäftigt oder der Provider drosselt). Eine Complaint entsteht, wenn jemand deine E-Mail als Spam markiert oder als unerwünscht meldet. Beides sind klare Signale, an diese Adresse nicht weiterzusenden — oder zumindest zu pausieren und nachzuforschen.
Ignorierst du diese Signale, verschlechtert sich die Zustellbarkeit schnell. Mailprovider lernen, dass deine Nachrichten Probleme verursachen, und zukünftig landen mehr E‑Mails im Spam — sogar bei guten Leads. Außerdem verschwendest du Geld, indem du an tote Adressen sendest, und Zeit, weil du Leuten nachläufst, die deine Nachricht nie gesehen haben.
Eine Bounce- und Complaint-Pipeline ist kein glitzerndes Analytics-Projekt. Sie ist ein kleines, verlässliches System, das:
- jedes Bounce- und Complaint-Event erfasst
- schlechte Adressen schnell suppressiert
- eine durchsuchbare Audit-Spur hinterlässt
Den letzten Punkt unterschätzt man leicht. Eine Woche später wird jemand fragen: „Haben wir diese Person wirklich angeschrieben?“ oder „Warum wurde diese Adresse suppressed?“ Wenn du nur ein einzelnes Suppression-Flag ohne Historie hast, kannst du das nicht mit Zuversicht beantworten.
Die folgende Einrichtung nutzt gängige AWS-Bausteine (SNS, SQS, Lambda), um Events zu erfassen, sicher zu verarbeiten und zu speichern. Sie behandelt nicht Copywriting, List-Quellen, Sending-Domains oder die vollständige SES-Konfiguration.
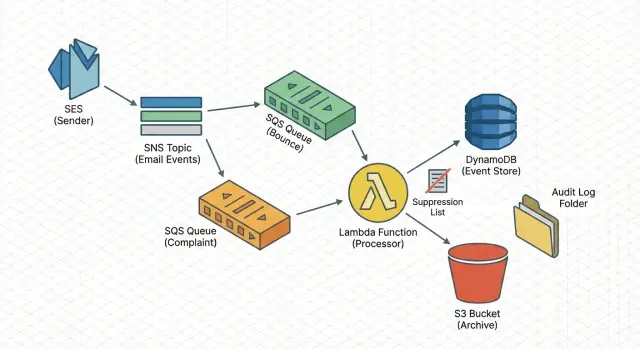
Die einfache Architektur auf einen Blick
Eine zuverlässige Pipeline sollte langweilig sein: jedes Event landet an einem sicheren Ort, wird auf wiederholbare Weise verarbeitet und hinterlässt einen Datensatz, den du später nachschlagen kannst.
Der Ablauf (Ingest -> Queue -> Work)
Ein bewährter Pfad ist:
SES sendet Bounce/Complaint-Benachrichtigungen an SNS, SNS liefert an SQS, und ein Lambda-Worker liest aus SQS.
Dieser Ansatz puffert Spitzen ab, übersteht kurze Ausfälle und erlaubt Retries ohne dein Sending zu blockieren.
Was der Worker macht
Halte die Lambda fokussiert. Sie sollte validieren, normalisieren, das Event schreiben und dann Side-Effects anwenden (wie Suppression). Typische Schritte:
- die Nutzlast validieren (fehlerhaftes JSON, fehlende E-Mail, fehlender Typ)
- dedupen mittels Event-ID oder eines stabilen Schlüssels wie message ID + Empfänger + Typ
- das Event klassifizieren (hard bounce, soft bounce, complaint)
- eine einfache Aktion anwenden (suppress, nur warnen, ignorieren)
- Kontext anhängen (sending domain, Mailbox, Campaign ID)
Speicherung + Aktionen (schnelle Abfrage und Audit)
Verwende zwei Speicherebenen: eine für schnelle Abfragen und eine für langfristigen Nachweis. Zum Beispiel:
- ein „letzter Status pro Adresse“-Datensatz für schnelle Lookups
- ein Archiv des rohen Event-Payloads für Audits und Debugging
Vom selben Worker aus kannst du auch Aktionen auslösen: Adresse zur Suppression-Liste hinzufügen, alarmieren bei Complaint-Spitzen und die Kampagne taggen, damit du nachvollziehen kannst, welche Nachricht das Problem verursacht hat. Das ist dasselbe Muster, das Tools wie LeadTrain verwenden, um Deliverability sauber zu halten, wenn sie über getrennte SES-Setups senden.
SES so einrichten, dass Bounce- und Complaint-Events veröffentlicht werden
Stelle zuerst sicher, dass SES die richtigen Signale aussendet, sobald eine E-Mail fehlschlägt oder ein Empfänger sich beschwert.
Erstelle in SES ein Configuration Set (oder verwende eines, das du bereits an ausgehende Mails anhängst) und aktiviere Event-Publishing für Bounce und Complaint. Halte das Payload so roh wie möglich. Du möchtest später Details: Timestamp, Message ID, Zieladresse, Bounce-Typ und Complaint-Feedback.
Behandle Umgebungen getrennt. Verwende ein SNS-Topic für Produktion und ein anderes für Staging, damit Testaktivitäten reale Metriken nicht verfälschen.
Eine einfache Einrichtung:
- Erstelle ein SNS-Topic pro Umgebung (z. B. ses-events-prod und ses-events-staging).
- In deinem Configuration Set veröffentliche Bounce- und Complaint-Events an das passende SNS-Topic.
- Abonniere SQS-Queues beim SNS-Topic. Viele Teams nutzen eine operative Queue für Suppression/Alerts und eine separate Queue für Reporting.
- Schränke die SQS-Queue-Policy so ein, dass nur dein SNS-Topic Nachrichten senden darf (nach SourceArn und Account beschränken).
- Sende eine kleine Testcharge und bestätige, dass du sowohl Bounce- als auch Complaint-Messages mit den erwarteten Feldern erhältst.
Events sicher mit SQS puffern
SQS ist der Sicherheits-Puffer zwischen SES-Events und deinem Code. Es entkoppelt das System, sodass ein Anstieg an Bounces oder Complaints deinen Worker nicht überlastet. Wenn Lambda ein paar Minuten down ist, warten die Events in der Queue, statt zu verschwinden.
Für die meisten Pipelines ist eine Standard-Queue die einfachste Wahl. Sie kann Nachrichten mehrmals zustellen, daher muss der Worker idempotent sein (sicher doppelt ausführbar). Wähle FIFO nur, wenn du wirklich strikte Reihenfolge oder Queue‑Level‑Deduplication brauchst.
Standard vs. FIFO in einfachen Worten
FIFO kann sinnvoll sein, wenn du brauchst:
- strikte Reihenfolge für dieselbe E-Mail-Adresse
- Deduplication auf Queue-Level
- vorhersehbares, geringeres Volumen, das nicht in FIFO-Limits läuft
Dead‑Letter-Queue und Retry-Limits
Nutze eine DLQ, damit Poison-Messages gesunde Nachrichten nicht blockieren. Ein sicherer Anfangswert:
- max receives: 5 bis 10
- Message-Retention: lang genug zur Untersuchung (einige Tage sind üblich)
- Alarme, wenn die DLQ-Tiefe > 0 ist
Halte Nachrichten klein, aber wirf keinen Kontext weg. Speichere das vollständige SES-Event-Payload (oder den vollständigen SNS-Message-Body), damit du später auditieren kannst. Wenn du Suppression-Regeln änderst, ist das originale Payload ausschlaggebend, um zu erklären, warum eine Adresse suppressed wurde.
Events mit einem kleinen Lambda-Worker verarbeiten
Der Lambda-Worker übersetzt SES-Events in die Entscheidungen, die dir wichtig sind. Halte die Aufgabe eng: parse eine Nachricht, extrahiere ein paar Felder, schreibe ein Event-Record und aktualisiere den Suppression-Status bei Bedarf.
Beginne damit, SES-Payloads in ein internes Schema zu normalisieren. Verschiedene Event-Typen sehen nicht immer gleich aus, also wähle eine konsistente Form und mappe alles hinein. Ein praktisches Minimum:
- event_type (bounce, complaint, delivery)
- message_id (SES mail.messageId)
- recipient_email
- event_time (ein einheitlicher Timestamp)
- source (Configuration Set, Sending Identity oder Systemname)
Normalisiere Bounce‑Typen früh. Behalte „bounce“ als Haupttyp und speichere hard vs. soft als separates Feld. Dasselbe für Complaints: subtype-Details kannst du aufbewahren, aber lass sie nicht deinen Kern‑Flow fragmentieren.
Idempotenz ist wichtig, weil SQS Nachrichten mehrfach liefern kann. Verwende einen stabilen Schlüssel wie message_id + recipient_email + event_type. Prüfe vor dem Schreiben, ob du diesen Schlüssel schon gespeichert hast. Wenn ja, acknowledge und beende. Das verhindert doppelte Suppression und hält Zählungen korrekt.
Sei strikt bei Timestamps. Speichere den Event‑Timestamp in einem einheitlichen Format (z. B. ISO-Strings). Speichere außerdem received_at separat, damit du Verzögerungen erkennen kannst.
Eine gute Faustregel: schreibe zunächst den Event-Record, dann wende Side‑Effects an. Wenn der Worker nach dem Schreiben, aber vor der Suppression fehlschlägt, kannst du die Suppression später sicher nachholen, ohne die Audit-Spur zu verlieren.
Events für Geschwindigkeit und Audit-Trail speichern
Du willst beides: schnelle Antworten („ist diese Adresse sicher zu mailen?“) und eine vollständige Papierspur, wenn etwas schief aussieht.
Speichere eine kleine Zusammenfassung, die du schnell abfragen kannst, und bewahre das rohe AWS-Payload separat auf. Das Roh‑Payload ist deine Quelle der Wahrheit, wenn du einen Complaint‑Spike erklären oder begründen musst, warum eine Adresse suppressed wurde.
Ein Summary-Record kann klein sein:
- event_id (deine eindeutige ID)
- message_id (von SES)
- recipient (E‑Mail-Adresse)
- type und subtype (bounce, complaint; hard/soft)
- reason (kurzer Text oder Code)
Eine gängige Kombination ist DynamoDB für schnelle Lookups und S3 für Archivierung. DynamoDB funktioniert gut, wenn dein Sending-Pfad schnell prüfen muss: „Hat dieser Empfänger zuvor gebounced?“ S3 ist günstig, um rohes JSON in großem Maßstab zu speichern.
Ein einfaches Muster: schreibe die Zusammenfassung in DynamoDB, speichere das rohe Payload in S3 unter einem Schlüssel mit Datum und message_id, und speichere diesen S3-Key im DynamoDB-Record.
Die Aufbewahrung ist eine Policy‑Entscheidung. Manche Teams behalten Zusammenfassungen langfristig und löschen Roh‑Payloads früher. Wenn du tiefe Audits brauchst, mach es umgekehrt.
Automatisch schlechte Adressen suppressen (Regeln einfach halten)
Auto‑Suppression ist der Punkt, an dem sich die Pipeline bezahlt macht. Das Ziel ist kein perfektes Modell, sondern bekannte schlechte Adressen schnell zu stoppen und später die Entscheidung erklären zu können.
Beginne mit Regeln, die leicht zu verteidigen sind:
- Hard Bounce: sofort suppressen.
- Complaint: sofort suppressen.
- Soft Bounce: nur suppressen nach N Events in einem Rolling Window (z. B. 3 Soft Bounces innerhalb von 7 Tagen).
- Unsubscribe (falls separat erfasst): sofort suppressen.
Soft Bounces sind knifflig, weil sie temporär sein können. Die Schwellenregel verhindert Überreaktionen auf einen schlechten Tag, entfernt aber Adressen, die wiederholt fehlschlagen.
Führe eine kleine Allowlist für interne Domains, Test-Inboxen und Seed-Adressen. Halte sie eng und überprüfe sie, damit sie echte Probleme nicht verdeckt.
Jede Suppression sollte auditierbar sein. Speichere:
- die Regel, die die Suppression ausgelöst hat
- das auslösende Event-Metadatum (Timestamp, Message ID, Bounce-Typ)
- den Kontext der Quelle (Campaign ID, Sending Domain, Mailbox)
Diese Papierspur macht Automation sicherer und macht Rücknahmen einfach, wenn jemand sagt: „Dieser Lead ist valide, bitte unsuppress.“
Eine vertrauenswürdige Suppression-Liste pflegen
Eine Suppression-Liste hilft nur, wenn alle sie als Quelle der Wahrheit behandeln. Das bedeutet zwei Dinge: ein klarer Status pro Empfänger und ein einziger Ort, den das Sending-System vor jedem Versand abfragt.
Viele Teams arbeiten gut mit drei Stati:
- active: ok zum Senden
- suppressed: nicht senden
- pending-review: pausiert, bis ein Mensch bestätigt
Der Sending-Pfad sollte nicht raten. Vor dem Versand einer E-Mail mache ein Lookup und blockiere den Send, wenn der Status suppressed oder pending-review ist. Leg diese Prüfung in den Service, der die Send-Liste baut, nicht in ein Dashboard, das jemand vergessen könnte.
Das Unsuppressen ist eine Fehlerquelle. Mach es möglich, aber bewusst: fordere einen Grund und protokolliere, wer es genehmigt hat. Wenn du mehrere Tools hast, halte es simpel: nur ein System darf den Suppression-Status ändern, und alle anderen müssen es aufrufen.
Überschreibe auch nicht die Historie. Jede Statusänderung sollte ein Audit‑Event erzeugen: was sich änderte, von was zu was, wann und was sie ausgelöst hat.
Beispiel: Eine Adresse hard bounct am Montag und wird automatisch suppressed. Am Donnerstag antwortet der Lead von einer korrigierten Adresse. Du lässt die alte Adresse suppressed, markierst die neue als aktiv und protokollierst beide Änderungen mit Notizen. In Plattformen wie LeadTrain hilft diese Historie, Reply‑Classification und Sending‑Logik auf einer konsistenten Suppression‑Entscheidung aufzubauen.
Häufige Fehler und wie du sie vermeidest
Eine Pipeline kann am ersten Tag fertig aussehen und später trotzdem falsche Entscheidungen treffen. Die meisten Probleme entstehen durch kleine Annahmen, die Metriken verzerren oder falsche Suppression auslösen.
Eine Falle ist, „delivered“ als „inbox“ zu behandeln. SES kann dir zeigen, dass der empfangende Server die Nachricht akzeptiert hat, nicht, wo sie gelandet ist. Nutze Delivery als Signal zur Send-Gesundheit, nicht als Beweis für Inbox-Platzierung.
Ein weiteres Problem ist, alle Bounces gleich zu behandeln. Ein transienter Bounce sollte nicht dieselbe Reaktion wie ein permanenter Bounce bekommen. Über‑Suppressing verkleinert deine Liste und kann echte Probleme wie Pacing, Content oder neue Domain‑Reputation verschleiern.
Häufige Fehler und Korrekturen:
- Keine Retries: wenn dein Worker einmal fehlschlägt, verschwindet das Event. Fix: SQS + Retries + DLQ + idempotente Verarbeitung.
- Kein Dedupe-Key: dasselbe Event wird zweimal verarbeitet. Fix: speichere eine eindeutige Event-ID und ignoriere Wiederholungen.
- Auf jeden Bounce suppressen: temporäre Probleme werden zu dauerhaften Strafen. Fix: sofort suppressen bei Hard Bounces und Complaints; Schwellen für Soft Bounces verwenden.
- Nur Aggregates speichern: du kannst nicht beantworten „Warum wurde das suppressed?“. Fix: rohe Events mit Message IDs, Timestamps und der ausgelösten Regel speichern.
- Annehmen, Delivery = Inbox: Metriken sehen gut aus, während Antworten sinken. Fix: trenne Delivered von Engaged und beobachte Antwortraten nach Mailbox und Domain.
Beispiel: Du sendest 2.000 E‑Mails und siehst 1.980 Delivered. Wenn 30 Soft Bounces von einer einzelnen Domain kommen und du sie sofort suppressst, entfernst du womöglich valide Leads. Eine bessere Regel ist: „suppress nur Hard Bounces und Complaints, Soft Bounces nur nach 3 Events in 7 Tagen“, und für jede Entscheidung ein Audit-Record anlegen.
Kurze Checkliste, damit die Pipeline gesund bleibt
Eine Pipeline hilft nur, wenn du ihr Woche für Woche vertrauen kannst.
Eine einfache Routine (täglich oder mehrmals pro Woche):
- Bestätige, dass Events fließen: die Queue-Tiefe sollte sich bewegen, wenn Bounces/Complaints passieren.
- Prüfe die DLQ: sie sollte normalerweise leer sein. Falls nicht, untersuche einige Nachrichten, behebe die Ursache und re‑playe sicher.
- Spot‑check Empfänger: wähle ein paar kürzlich gesendete Adressen und prüfe, ob du deren Event-Historie und Timestamps sehen kannst.
- Verifiziere, dass Suppression vor dem Senden durchgesetzt wird: Suppression‑Checks sollten passieren, bevor eine E‑Mail in die Send‑Queue gelegt wird.
- Probiere wöchentlich einen Audit-Export: bestätige, dass Schlüsselfelder vorhanden sind (Recipient, Event-Typ, Reason-Codes, Message ID, Campaign ID, Timestamp).
Ein schneller Spot‑Check, der gut funktioniert: wähle 3 Adressen, die gebounced haben, und 2, die geantwortet haben. Du solltest jede von der versuchten Send bis zum Endergebnis zurückverfolgen können, ohne raten zu müssen, welches System die Wahrheit hat.
Wenn du Outbound über eine Plattform wie LeadTrain betreibst, ist das Ziel dasselbe: die Event-Spur vollständig halten und Suppression automatisch machen, damit dein Team Zeit mit guten Leads verbringt, statt Datenlücken zu stopfen.
Beispiel: eine reale Outreach-Woche
Ein kleines SDR-Team fährt eine 600‑E‑Mail-Sequenz an eine gezielte Liste. Ihre Pipeline ist bereits verdrahtet, sodass jeder Bounce und jede Complaint erfasst, gespeichert und bearbeitet wird, ohne dass jemand ständig draufschaut.
Am Montag bounce eine Adresse hard (User existiert nicht). Innerhalb von Sekunden wird das Event gespeichert und die Adresse suppressed. Der nächste Schritt in der Sequenz versucht Mittwoch zu senden, aber der Versand wird blockiert, bevor er das System verlässt. Keine wiederholten Bounces, kein zusätzlicher Schaden.
Am Donnerstag markiert ein anderer Prospect nach der ersten Mail „Report spam“. Complaints sind dringend, daher wird die Adresse sofort suppressed, selbst wenn ein Follow‑Up später am Tag geplant war.
Das Event-Log des Teams könnte so aussehen:
- Mon 10:14:12 - Hard bounce - [email protected] - suppressed (reason: bounce)
- Wed 09:00:03 - Send blocked - [email protected] - already suppressed
- Thu 15:27:40 - Complaint - [email protected] - suppressed (reason: complaint)
- Fri 11:05:18 - Manager review - why did alex stop? - full trail shown
Am Freitag fragt ein Manager, warum [email protected] keine Mails mehr bekommt. Statt zu raten zeigst du das Bounce-Payload, die Suppression‑Aktion und den späteren blockierten Send‑Versuch. Das ist der Unterschied zwischen „es ist verschwunden“ und „hier ist die Ereigniskette“.
Fehler passieren auch. Wenn der Bounce durch einen Tippfehler in der hochgeladenen Liste verursacht wurde und die korrekte Adresse [email protected] lautet, lösche nichts heimlich. Behalte einen genehmigten Unsuppress‑Eintrag (wer es angefordert hat, wann und warum) und füge die korrigierte Adresse als neuen Empfänger hinzu.
Nächste Schritte: Kleine Version ausliefern und iterieren
Wähle zu Beginn ein Ziel, das du zuerst auslieferst: zuverlässige Ingestion, langlebige Speicherung oder automatische Suppression. Alles drei am ersten Tag perfekt machen ist eine gute Methode, um Projekte aufzuschieben.
Eine praktische Reihenfolge ist: zuerst Ingestion (keine Daten verlieren), dann Speicherung (Fragen später beantworten), dann Suppression (handeln).
Eine kleine Erstversion, die trotzdem wirkt:
- Erfasse SES Bounce- und Complaint-Events in einer Queue und logge jede Nachricht.
- Speichere das rohe Payload plus einige normalisierte Felder (Timestamp, Typ, Mailbox, message_id).
- Wende anfangs nur zwei Suppression-Aktionen an: Hard Bounces und Complaints.
- Füge eine einfache Abfrage hinzu: „Warum wurde diese Adresse suppressed?"
Halte die Regeln für eine Woche klein, und erweitere sie dann basierend auf dem, was du tatsächlich siehst. Wenn für eine Domain transient Bounces hochgehen, könntest du eine temporäre Pause‑Regel für diese Domain hinzufügen, statt jede Adresse zu suppressen.
Schreibe dein Event‑Schema und deine Suppression‑Regeln in klarem Deutsch und bewahre sie an einem Ort auf, den das Team tatsächlich liest.
Wenn du weniger bewegliche Teile willst, ist LeadTrain ein Beispiel für eine All‑in‑One Cold‑Email‑Plattform, die Domains, Mailboxes, Warm‑up, Sequenzen und Reply‑Classification in einen Workflow bringt — und dabei auf dieselben Grundlagen setzt: genaue Events, schnelle Suppression und eine klare Audit‑Spur.
FAQ
Was ist der Unterschied zwischen einem Bounce und einer Complaint, und warum ist das wichtig?
Ein Bounce bedeutet, dass die E-Mail nicht zugestellt werden konnte; eine Complaint bedeutet, dass der Empfänger deine Nachricht als Spam oder unerwünscht gemeldet hat. Praktisch gilt: Behandle beides als Signal „nicht mehr senden“, denn ignoriert man diese Hinweise, verschlechtert sich schnell die Zustellbarkeit und du verschwendest Sends.
Was ist das einfachste AWS-Setup, um SES-Bounces und -Complaints zu erfassen?
Beginne mit dem soliden, zuverlässigen Weg: SES veröffentlicht Bounce- und Complaint-Events an SNS, SNS verteilt an SQS, und eine Lambda liest aus SQS. So gehst du nicht bei Spitzen oder kurzen Ausfällen verloren und kannst Retries sicher handhaben.
Sollte ich Produktion und Staging für SES-Event-Pipelines trennen?
Verwende separate SNS-Topics und Queues pro Umgebung, damit Test-Bounces und -Complaints Produktionsdaten nicht verunreinigen. Das macht Debugging auch sicherer, weil du Regeln in Staging ändern kannst, ohne die echte Suppression-Liste zu gefährden.
Sollte ich für SES-Events eine SQS Standard-Queue oder FIFO verwenden?
Eine Standard-Queue ist die Default-Wahl, weil sie skaliert und einfach ist, liefert Nachrichten aber gelegentlich mehrfach aus. Das ist in Ordnung, solange deine Lambda idempotent ist — also wiederholte Verarbeitung desselben Events nichts kaputtmacht.
Wie gehe ich mit schlechten oder fehlerhaften SES-Events um, ohne die Pipeline zu unterbrechen?
Nutze eine Dead‑Letter-Queue, damit fehlerhafte Nachrichten den Fluss nicht blockieren, und setze eine Max-Receive-Grenze wie 5–10. Wenn die DLQ Dinge ansammelt, untersuche die Ursache und replaye erst, nachdem Parsing/Validation behoben ist, sonst schlägst du dieselben Nachrichten wieder fehl.
Was sollte meine Lambda-Worker tun (und was nicht)?
Halte die Lambda-Aufgabe eng begrenzt: validiere das Payload, normalisiere Felder in ein internes Schema, dedupe mit einem stabilen Schlüssel, speichere das Event und wende dann Side-Effects wie Suppression an. Schreibe das Event vor der Suppression, so bleibt die Audit-Spur erhalten, falls die Funktion abstürzt.
Wie verhindere ich doppelte Verarbeitung, wenn SQS dieselbe Nachricht mehrmals zustellt?
Gehe davon aus, dass Duplikate passieren und dedupe mit einem stabilen Schlüssel wie message_id + recipient_email + event_type. Speichere diesen Schlüssel und behandle Wiederholungen als No‑Ops, damit du nicht doppelt suppressst oder Bounce-/Complaint-Zahlen verfälschst.
Wie sollte ich Events speichern, damit ich schnell abfragen und später auditieren kann?
Behalte zwei Ebenen: einen schnellen „letzten Status pro Adresse“-Eintrag für Send-Time-Checks und ein Roh-Event-Archiv für Audits und Debugging. Ein gängiges Muster ist eine Zusammenfassung in DynamoDB plus das rohe JSON in S3, wobei der S3-Objektschlüssel im DynamoDB-Datensatz gespeichert wird.
Was sind gute Standard-Regeln zur Auto-Suppression für Bounces und Complaints?
Starte mit Regeln, die leicht zu verteidigen sind: suppressiere Hard Bounces und Complaints sofort; suppressiere Soft Bounces nur nach einer Schwelle (z. B. 3 innerhalb von 7 Tagen). Speichere die Regel, die die Suppression ausgelöst hat, zusammen mit Message ID und Timestamp, damit Entscheidungen erklärbar bleiben.
Wie stelle ich sicher, dass Suppression tatsächlich durchgesetzt wird und sicher umkehrbar ist?
Behandle die Suppression-Liste als Quelle der Wahrheit und führe die Überprüfung bei jedem Send aus, nicht in einem Dashboard, das jemand vergessen könnte. Erlaube Un‑Suppression, aber nur mit Begründung und Genehmigungsprotokoll, und behalte die historischen Events vollständig.