Von der AWS SES-Sandbox zur Produktion für ausgehende E-Mails: Ein Plan
Schritte von der AWS SES-Sandbox in die Produktion für ausgehende E-Mails, plus ein praxisorientierter Plan für Limits, Hochfahren und Monitoring, damit Sie bei zunehmendem Volumen nicht blockiert werden.
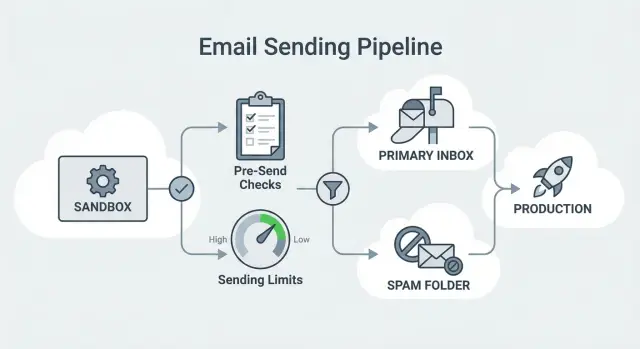
Warum die SES-Sandbox ausgehende Skalierungen blockiert
Wenn Sie Amazon Simple Email Service (SES) erstellen (oder neu aktivieren), startet Ihr Konto meist in der SES-Sandbox. Das ist ein Sicherheitsmodus: AWS lässt Sie senden testen, setzt aber enge Leitplanken, bis Sie nachweisen, dass Sie verantwortungsvoll senden.
Diese Leitplanken sind ein echtes Problem für Cold Outreach. In der Sandbox sind Sie durch ein geringes Tagesvolumen, niedrige Sende-Geschwindigkeit pro Sekunde und — am wichtigsten — nur verifizierte Empfänger eingeschränkt. Letzteres blockiert Outbound völlig: Sie können echte Prospects nicht anschreiben, solange Sie nicht jede Adresse oder Domain zuvor verifiziert haben.
Deshalb stoßen Teams beim Wechsel „AWS SES Sandbox zu Produktion" oft auf Reibung. Sie können Ihre Sequenz bereit haben, Ihre Liste importiert und einen Ramp-Plan erstellt haben und trotzdem feststellen, dass Ihre erste Charge nicht gesendet wird — oder so langsam sendet, dass Follow-ups auseinanderlaufen und die Kampagne Momentum verliert.
Ein typisches Fehlerbild sieht so aus:
- Tests an ein paar internen Adressen funktionieren, alles scheint bereit.
- Launch zu Prospects scheitert, weil Empfänger nicht verifiziert sind.
- Nach der Genehmigung ist die Sende-Rate noch so niedrig, dass Schritte sich verteilen und Ergebnisse einbrechen.
- Wenn Sie das Volumen erhöhen, erzwingen Throttling-Fehler Pausen, während Sie höhere Limits anfordern.
Das trifft SDR-Teams und Gründer besonders hart, weil sie stetigen täglichen Durchsatz brauchen. Wenn Ihr Plan auf konsistentem Senden beruht (zum Beispiel 200 neue Prospects pro Tag über mehrstufige Sequenzen), macht die Sandbox Outreach zu Stop-and-Go-Arbeit.
Ein weiteres Detail: Die Sandbox ist kein realistischer Deliverability-Test. Reale Zustellbarkeit hängt von Authentifizierung, Warm-up, Listenqualität, Bounce-/Complaint-Kontrolle und einem schrittweisen Hochfahren ab. Die Sandbox existiert hauptsächlich, um Sie zu bremsen, bis AWS sicher ist, dass Sie keinen Missbrauch oder schlechte Empfängererfahrungen erzeugen.
Sandbox vs. Produktion: Was sich wirklich ändert
Sandbox und Produktion unterscheiden sich in den Punkten, die für Outbound am wichtigsten sind.
In der Sandbox dürfen Sie nur an verifizierte Identitäten senden (spezifische E-Mail-Adressen oder ganze Domains, die Sie verifiziert haben). In der Produktion können Sie an echte Empfänger senden, ohne jeden einzelnen zu verifizieren.
Ihre Limits ändern sich ebenfalls. Sandbox-Quoten sind klein. Produktionsquoten sind höher, aber weiterhin durchsetzbar. Sie können weiterhin auf Tageslimits und Per-Sekunde-Throttles stoßen, und AWS kann Limits anhand Ihrer Sendehistorie anpassen.
Der andere große Unterschied ist Reputation. In der Sandbox bauen Sie keine aussagekräftige Historie auf. In der Produktion beginnen Bounce- und Beschwerderaten, Ihre langfristige Skalierbarkeit zu formen.
In der Praxis spüren Outbound-Teams drei unmittelbare Unterschiede:
- Wen Sie erreichen können: nur verifiziert vs. offen senden
- Wie schnell Sie senden können: niedrige Caps vs. höhere (aber begrenzte) Quoten
- Wie sehr Fehler zählen: Produktionsmetriken beeinflussen schnell Reputation und Durchsatz
Was AWS tatsächlich bewertet
Wenn Sie Produktionszugang beantragen (und nachdem Sie genehmigt wurden), schaut AWS nach Signalen, dass Sie Empfänger oder Netzwerke nicht schädigen werden. Zwei Metriken sind am wichtigsten:
- Bounce-Rate: Hohe Bounces deuten meist auf schlechte Listenhygiene hin.
- Beschwerderate: Beschwerden deuten auf unerwünschte Mail, unklare Zielgruppenansprache oder irreführende Inhalte hin.
AWS interessiert sich außerdem für Ihren Use Case und wie Sie Opt-outs handhaben. Beim Outbound bedeutet das in der Regel: E-Mail an Personen, die vernünftigerweise mit einer Nachricht von Ihnen rechnen könnten, und eine einfache Möglichkeit, den Empfang zu stoppen.
Produktionszugang ist nicht die Ziellinie. Es ist die Erlaubnis, in echtem Maßstab zu operieren. Wenn Sie zu schnell hochfahren, Abmeldungen ignorieren oder an schlechten Listen senden, können Sie trotzdem gedrosselt oder zum Verlangsamen gezwungen werden.
Pre-Flight: Einrichtung vor dem Antrag
Bevor Sie AWS bitten, Sie aus der Sandbox in die Produktion zu versetzen, bauen Sie Ihre Sendegrundlage auf. SES-Genehmigungen (und langfristige Stabilität) sind viel einfacher, wenn Ihre Identität und Prozessabläufe durchdacht aussehen.
Beginnen Sie mit einer dedizierten Sending-Domain, die getrennt von Ihrer Hauptfirma-Domain ist. Viele Teams nutzen eine eng verwandte Domain, damit Outbound-Experimente die Reputation des primären Postfachs nicht gefährden.
Richten Sie dann Authentifizierung ein: SPF, DKIM und DMARC. Am ersten Tag brauchen Sie keine aggressive DMARC-Policy, aber Sie brauchen Ausrichtung. Ein einfacher Zielzustand ist:
- SES DKIM-Signatur stimmt mit der Domain im From-Feld überein
- SPF ist veröffentlicht
- DMARC ist veröffentlicht, damit Provider Legitimität prüfen können
Entscheiden Sie außerdem vorab über Identität und Reply-Handling:
- Verwenden Sie einen From-Namen, der wie eine echte Person oder ein Team wirkt.
- Verwenden Sie eine Adresse, die Antworten empfangen kann.
- Halten Sie From-Details stabil (rotieren Sie Namen und Adressen nicht wöchentlich).
Schließlich verpflichten Sie sich zu einer klaren Unsubscribe-Regel. Auch beim Cold Outbound muss „Stop“ sofort und konsistent über alle Listen und Sequenzen hinweg bedeuten: stoppen.
Wenn Sie eine einfachere Ops-Einrichtung möchten, ist LeadTrain (leadtrain.app) darauf ausgelegt, Domains, Mailboxes, Warm-up, Sequenzen und Reply-Classification an einem Ort zu halten, damit während der Einrichtung weniger Details untergehen.
Schritt-für-Schritt: Produktionszugang in SES beantragen
Der Wechsel in die Produktion ist eine Support-Anfrage. Ihre Antworten sind genauso wichtig wie die technische Einrichtung.
1) Finden Sie das Formular in der AWS-Konsole
Öffnen Sie Amazon SES in der AWS-Region, aus der Sie senden werden. Im Bereich Account-Status (wo angezeigt wird, dass Sie in der Sandbox sind) wählen Sie die Option, Produktionszugang oder eine Erhöhung des Sende-Limits zu beantragen. Das öffnet ein Support-Case-Formular.
2) Beschreiben Sie Ihren Use Case in einfacher Sprache
Seien Sie spezifisch und leicht verständlich. Erklären Sie, wen Sie mailen, warum Sie sie mailen, wie Sie die Adressen erhalten haben und wie Empfänger sich abmelden können.
Die überzeugendsten Anfragen decken meist ab:
- Zielgruppe: Wen Sie anschreiben (z. B. B2B-Prospects, die Ihrem ICP entsprechen)
- Quelle: Wie Adressen beschafft wurden (manuelle Recherche, geprüfter Provider, eigene Anmeldungen)
- Opt-out: Wie Leute Nachrichten stoppen können (Link oder „reply stop“) und wie schnell Sie das umsetzen
- Ramp: Wie Sie klein anfangen und schrittweise erhöhen
- Hygiene: Was Sie mit Bounces und Beschwerden tun
3) Liefern Sie, was AWS typischerweise nachfragt
Erwarten Sie Fragen nach Beispiel-Betreffzeilen und Inhalten, Ihrer Firmenidentität, Ihrer Website und wie Sie irreführende Messages vermeiden. Oft wollen sie genau wissen, wie Sie mit Hard Bounces, Beschwerden und Abmeldungen umgehen.
4) Bei Ablehnung oder Rückfragen
Senden Sie nicht denselben Text erneut. Gehen Sie auf den konkreten Einwand ein (meist Listenqualität, Opt-out-Klarheit oder unklarer Use Case). Falls nötig, beantragen Sie zuerst ein kleineres Limit und erhöhen es später, wenn Sie stabile Metriken vorweisen können.
Planen Sie Ihre Sende-Limits, damit Sie keine Decke treffen
Vom AWS SES Sandbox-Status in die Produktion zu kommen ist nur die halbe Miete. Die andere Hälfte ist sicherzustellen, dass Ihr Outreach-Plan zu Ihren SES-Quoten passt.
Outbound-Volumen ist nicht einfach „Leads x 1 E-Mail“. Es sind neue Prospects plus Follow-ups in einer Sequenz, verteilt auf aktive Sender.
Eine einfache Methode zur Abschätzung des Tagesvolumens:
- Zählen Sie aktive Send-Mailboxes.
- Multiplizieren Sie mit neuen Prospects pro Mailbox und Tag.
- Multiplizieren Sie mit der durchschnittlichen Anzahl E-Mails, die ein Prospect tatsächlich erhält (Initial + Follow-ups).
- Fügen Sie einen Puffer (20–30%) für ungleiche Tage und Retries hinzu.
Beispiel: 6 SDRs starten jeweils 40 neue Prospects pro Tag. Jeder Prospect erhält im Zeitverlauf etwa 3 E-Mails. Das sind 6 x 40 x 3 = 720 E-Mails/Tag. Mit Puffer planen Sie auf rund 900.
Berücksichtigen Sie auch Listenqualität. Bounces zählen weiterhin als Sends. Wenn eine Listenquelle höhere Bounces erzeugt, verbrauchen Sie schneller Kontingent und schädigen gleichzeitig die Reputation.
Beim Hochfahren starten Sie langsamer als Ihr Ziel, selbst wenn SES Ihnen Spielraum gibt. Ein konservatives wöchentliches Hochfahr-Schema schützt die Reputation oft genug:
- Tage 1–2: 10–20% des Zielvolumens
- Tage 3–4: 30–50%
- Tage 5–7: 60–80%
- Woche 2: Richtung 100%, wenn Metriken stabil bleiben
Beantragen Sie frühzeitig höhere Limits, wenn Sie erwarten, Ihre Quote in den nächsten 2–4 Wochen zu erreichen (z. B. wenn Sie bald Plätze hinzufügen oder Ihre Sequenz kurz vor dem steady-state Follow-up-Volumen steht).
Monitoring, das Sie in der Produktion hält
Sobald Sie in Produktion sind, geht es vor allem darum, Ihre Signale sauber und vorhersehbar zu halten.
Ein einfaches Wochen-Dashboard
Überprüfen Sie wöchentlich (und täglich während des Hochfahrens) eine kleine Metrik-Auswahl:
- Delivery-Rate
- Hard-Bounce-Rate
- Soft-Bounce-Rate
- Complaint-Rate
- Unsubscribe-Rate
Wenn die Zustellung sinkt und Bounces steigen, vermuten Sie Listenqualität oder Authentifizierungsprobleme. Wenn Beschwerden steigen, prüfen Sie Targeting, Frequenz oder Copy.
Frühwarnzeichen und Gegenmaßnahmen
Throttling zeigt sich meist nach wiederholten Metrikverschiebungen, nicht an einem einzelnen schlechten Tag. Achten Sie auf Muster wie steigende Bounce-Raten nach einem neuen Listen-Upload oder Beschwerden nach einer Copy-Änderung.
Halten Sie einfache Regeln, damit Sie nicht in Echtzeit diskutieren müssen:
- Bei steigendem Beschwerdeaufkommen pausieren Sie das neueste Segment und prüfen Targeting und Messaging.
- Bei steigenden Hard-Bounces stoppen Sie die jeweilige Listenquelle und reinigen die Daten, bevor Sie weitermachen.
- Wenn Soft-Bounces mehrere Tage erhöht bleiben, verlangsamen Sie das Hochfahren, bis es sich beruhigt.
Ein kurzes Änderungsprotokoll hilft enorm. Vermerken Sie größere Änderungen (neue Domain, neue Listquelle, neue Betreffzeilen, Volumensteigerung). Wenn Metriken sich bewegen, wissen Sie schneller, was es ausgelöst hat.
Bounce-, Beschwerde- und Abmelde-Handling für Outbound
Nach dem Wechsel von Sandbox zu Produktion ist die schnellste Art, Momentum zu verlieren, Bounces, Beschwerden und Abmeldungen zu ignorieren. SES beobachtet diese Raten genau, und Mailbox-Provider tun das ebenfalls.
Bounces: Hard vs. Soft
Hard Bounces sind permanente Fehler (Mailbox existiert nicht, Domain ungültig). Unterdrücken Sie diese sofort und versuchen Sie nicht erneut.
Soft Bounces sind meist temporär (Mailbox voll, temporärer Fehler, Ratenbegrenzung). Retryen Sie vorsichtig. Wenn dieselbe Adresse wiederholt soft bounced, unterdrücken Sie sie.
Eine sichere Regel:
- Hard Bounce: dauerhaft unterdrücken.
- Wiederholter Soft Bounce: nach wenigen Fehlversuchen unterdrücken.
- Plötzlicher Bounce-Anstieg: pausieren und diagnostizieren, bevor weitergesendet wird.
Beschwerden und Abmeldungen
Beschwerden („Als Spam melden") sind ein starkes negatives Signal. Die beste Prävention ist genaues Targeting und klare Erwartungen, nicht clevere Formulierungen.
Abmeldungen sind beim Outbound normal. Behandeln Sie sie wie verpflichtend. Wenn sich jemand abmeldet, unterdrücken Sie die Adresse sofort in allen Sequenzen und Listen.
Häufige Fehler, die Throttling oder Blocks auslösen
Viele Teams werden genehmigt und bekommen dann Probleme, weil die erste Woche nicht zu dem passt, was sie AWS beschrieben haben.
Die Muster, die am häufigsten Throttling auslösen:
- Volumen nach der Genehmigung zu schnell hochfahren
- Schwache Listenquellen verwenden (alt, gescrapt, unbestätigt)
- Zu viele Variablen während des Hochfahrens gleichzeitig ändern (Domain, Angebot, Zielgruppe und Volumen auf einmal)
- Negative Signale ansammeln lassen (langsames Abmelden, wiederholte Bounces)
- Cold Outbound mit wichtigen Transaktionsmails auf derselben Domain mischen
Um sicher zu bleiben: Ändern Sie jeweils nur eine Sache, fahren Sie vorhersehbar hoch und halten Sie Outbound getrennt von Transaktionsmails.
Beispiel: Ein kleines Outbound-Team in SES Produktion bringen
Betrachten Sie ein Team von 3 SDRs mit einer 14-tägigen Sequenz. Jeder SDR fügt 25 neue Prospects pro Tag hinzu. Wenn die Sequenz im Schnitt etwa 4 E-Mails pro Prospect umfasst, sieht die steady-state Rechnung so aus:
- Neue Prospects/Tag: 3 x 25 = 75
- Durchschnittliche E-Mails pro Prospect: 4
- Erwartete tägliche Sends im steady state: 75 x 4 = 300 E-Mails/Tag
Es wird nicht am Tag 1 mit 300 starten. Follow-ups stapeln sich über die Zeit, sodass das Volumen steigt, während die Sequenz geladen wird. Deshalb sollte Ihr Produktionsplan ein Hochfahren beinhalten, nicht nur einen Schalter.
Ein realistischer Ramp könnte sein:
- Tage 1–2: Limit bei 60–80/Tag insgesamt
- Tage 3–4: Limit bei 120–160/Tag
- Tage 5–7: Limit bei 200–250/Tag
- Woche 2: Annäherung an steady state (rund 300/Tag)
Wenn Beschwerden mitten im Ramp ansteigen (z. B. 2 Beschwerden bei 150 Sends), drücken Sie nicht weiter. Stoppen Sie das Wachstum für 48 Stunden, reduzieren Sie das Volumen um 30–50%, schärfen Sie Targeting und Copy und prüfen Sie, ob Opt-out korrekt funktioniert.
Kurze Checkliste und nächste Schritte
Die meisten „AWS SES Sandbox zu Produktion“-Probleme entstehen durch fehlende Grundlagen, die später als Bounces, Beschwerden oder Throttling sichtbar werden.
Schneller 5-Minuten-Check:
- Produktionszugang ist genehmigt und die From-Domain-Identität ist verifiziert.
- SPF, DKIM und DMARC sind veröffentlicht und mit der From-Domain ausgerichtet.
- Ein Ramp-Plan existiert (tägliche Caps und schrittweise Erhöhungen), der zu Ihren SES-Limits passt.
- Monitoring ist eingerichtet, mit einem benannten Owner.
- Bounces, Beschwerden und Abmeldungen werden sofort unterdrückt.
Wenn Sie schnellere Antworten möchten, wenn AWS Rückfragen stellt (oder wenn Metriken kippen), dokumentieren Sie intern drei Dinge: Ihre Listquelle, Ihren Ramp-Plan und Ihre genaue Opt-out-Regel.
Ein praktischer nächster Schritt ist eine einwöchige Produktionsprobe: eine Domain, ein kleiner Mailbox-Pool, ein enges Segment aktueller Leads und konservative Caps. Wenn die Signale sauber bleiben, fahren Sie hoch. Wenn nicht, pausieren, Fehler beheben und langsamer wieder starten.
FAQ
Why does Amazon SES start in the sandbox, and why is it a problem for outbound?
Die SES-Sandbox ist ein Sicherheitsmodus. Sie begrenzt das tägliche Volumen und die Sende-Geschwindigkeit und erlaubt nur das Senden an verifizierte Empfänger, was echtes Cold Outreach unmöglich macht, bis Sie Produktionszugang erhalten.
What does “verified recipients only” actually mean in SES sandbox?
In der Sandbox liefert SES nur an Identitäten, die Sie verifiziert haben, z. B. eine bestimmte E-Mail-Adresse oder eine Domain, die Sie kontrollieren. Prospects sind nicht verifiziert, deshalb schlagen Sends fehl, selbst wenn Templates und Sequenzen bei internen Tests korrekt aussehen.
What changes when SES moves from sandbox to production?
Sie können ohne Einzelverifizierung an alle senden, und Ihre Kontingente sind höher als in der Sandbox. Sie unterliegen aber weiterhin Tageslimits und Per-Sekunde-Throttles, und Bounce- sowie Beschwerderaten beginnen, Ihre Skalierbarkeit zu beeinflussen.
What should I set up before I apply for SES production access?
Richten Sie eine dedizierte Sending-Domain ein und veröffentlichen Sie SPF, DKIM und DMARC, sodass Ihre From-Domain mit der Authentifizierung übereinstimmt. Stellen Sie sicher, dass Ihre From-Adresse Antworten empfangen kann, die Identität stabil bleibt und der Abmelde-Prozess klar und sofort umgesetzt wird.
What should I write in the AWS SES production access request for cold outreach?
Beschreiben Sie, wen Sie mailen, warum die Empfänger mit Ihrer Nachricht rechnen könnten, wie Sie die Adressen erhalten haben und wie Opt-outs funktionieren. Fügen Sie einen realistischen Ramp-Plan hinzu und erklären Sie, wie Sie Bounces, Beschwerden und Abmeldungen behandeln — AWS prüft, ob Sie verantwortungsbewusst senden können.
What metrics does AWS care about most after I’m approved?
Die wichtigsten Kennzahlen sind Bounce-Rate und Beschwerderate, weil sie direkt auf Listenqualität und Empfängererfahrung hinweisen. AWS erwartet außerdem klare Opt-out-Prozesse und nicht-irreführende Nachrichten, damit Empfänger leicht aufhören können.
How do I calculate the sending limits I’ll actually need?
Schätzen Sie die Gesamtsendungen, nicht nur neue Leads, weil Follow-ups sich über eine mehrstufige Sequenz summieren. Multiplizieren Sie aktive Mailboxes mit neuen Prospects pro Mailbox/Tag und mit der durchschnittlichen Anzahl E-Mails pro Prospect, und fügen Sie einen Puffer hinzu, damit Sie nicht mitten in der Woche an die Quote stoßen.
How fast should I ramp volume after moving to production?
Starten Sie unter Ihrem Zielvolumen, auch wenn SES mehr erlaubt, und erhöhen Sie schrittweise, solange Bounces und Beschwerden stabil bleiben. Zu schnelles Hochfahren kann Throttling auslösen, Follow-ups auseinanderziehen und frühe Reputation schädigen.
What’s the safest way to handle bounces, complaints, and unsubscribes in SES?
Hard Bounces sofort unterdrücken und nicht erneut versuchen — wiederholte Fehler verschwenden Kontingent und schaden Metriken. Abmeldungen sofort über alle Sequenzen und Listen hinweg beachten. Spam-Beschwerden sind ein klares Signal: pausieren und untersuchen Sie Zielgruppe, Copy und Frequenz.
How do I avoid throttling or blocks after I get production access?
Führen Sie jeweils nur eine klare Änderung durch und halten Sie ein kurzes Änderungsprotokoll (neue Domain, neue Listquelle, neue Betreffzeile, Volumenänderung). Tools, die Domains, Warm-up, Sequenzen und Reply-Classification zusammenhalten — etwa LeadTrain — reduzieren Fehlkonfigurationen beim Hochfahren.